import fastcore
import pandas as pd
import pathlib
from fastcore.all import *
from fastcore.imports import *
import os
import sys
import sklearn
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score, cross_val_predict, KFold, train_test_split, cross_validate
from sklearn.metrics import ConfusionMatrixDisplay, accuracy_score, confusion_matrix
from IPython.display import display
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoderImport public packages
Import private packages
is_kaggle = 'kaggle_secrets' in sys.modulesif is_kaggle:
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
os.environ['KAGGLE_USERNAME'] = user_secrets.get_secret("kaggle_username")
if not os.environ['KAGGLE_USERNAME']: raise Exception("Please insert your Kaggle username and key into Kaggle secrets")
os.environ['KAGGLE_KEY'] = user_secrets.get_secret("kaggle_key")
github_pat = user_secrets.get_secret("GITHUB_PAT")
!pip install -Uqq git+https://{github_pat}@github.com/Rahuketu86/aiking
else:
from aiking.data.external import *
path = untar_data("kaggle_competitions::titanic");
print(path.ls())[Path('/Users/rahul1.saraf/rahuketu/programming/AIKING_HOME/data/titanic/test.csv'), Path('/Users/rahul1.saraf/rahuketu/programming/AIKING_HOME/data/titanic/train.csv'), Path('/Users/rahul1.saraf/rahuketu/programming/AIKING_HOME/data/titanic/gender_submission.csv')]from aiking.ml.structured import *Read the Dataset
data_dir = pathlib.Path(os.getenv('DATA_DIR', "/kaggle/input"));
path = data_dir/"titanic"
path.ls()(#3) [Path('/Users/rahul1.saraf/rahuketu/programming/AIKING_HOME/data/titanic/test.csv'),Path('/Users/rahul1.saraf/rahuketu/programming/AIKING_HOME/data/titanic/train.csv'),Path('/Users/rahul1.saraf/rahuketu/programming/AIKING_HOME/data/titanic/gender_submission.csv')]df_train = pd.read_csv(path/"train.csv"); df_train.head()
df_test = pd.read_csv(path/"test.csv"); df_test.head()| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | Kelly, Mr. James | male | 34.5 | 0 | 0 | 330911 | 7.8292 | NaN | Q |
| 1 | 893 | 3 | Wilkes, Mrs. James (Ellen Needs) | female | 47.0 | 1 | 0 | 363272 | 7.0000 | NaN | S |
| 2 | 894 | 2 | Myles, Mr. Thomas Francis | male | 62.0 | 0 | 0 | 240276 | 9.6875 | NaN | Q |
| 3 | 895 | 3 | Wirz, Mr. Albert | male | 27.0 | 0 | 0 | 315154 | 8.6625 | NaN | S |
| 4 | 896 | 3 | Hirvonen, Mrs. Alexander (Helga E Lindqvist) | female | 22.0 | 1 | 1 | 3101298 | 12.2875 | NaN | S |
EDA
display(df_train.describe(include='number').T, df_test.describe(include='number').T)| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| PassengerId | 891.0 | 446.000000 | 257.353842 | 1.00 | 223.5000 | 446.0000 | 668.5 | 891.0000 |
| Survived | 891.0 | 0.383838 | 0.486592 | 0.00 | 0.0000 | 0.0000 | 1.0 | 1.0000 |
| Pclass | 891.0 | 2.308642 | 0.836071 | 1.00 | 2.0000 | 3.0000 | 3.0 | 3.0000 |
| Age | 714.0 | 29.699118 | 14.526497 | 0.42 | 20.1250 | 28.0000 | 38.0 | 80.0000 |
| SibSp | 891.0 | 0.523008 | 1.102743 | 0.00 | 0.0000 | 0.0000 | 1.0 | 8.0000 |
| Parch | 891.0 | 0.381594 | 0.806057 | 0.00 | 0.0000 | 0.0000 | 0.0 | 6.0000 |
| Fare | 891.0 | 32.204208 | 49.693429 | 0.00 | 7.9104 | 14.4542 | 31.0 | 512.3292 |
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| PassengerId | 418.0 | 1100.500000 | 120.810458 | 892.00 | 996.2500 | 1100.5000 | 1204.75 | 1309.0000 |
| Pclass | 418.0 | 2.265550 | 0.841838 | 1.00 | 1.0000 | 3.0000 | 3.00 | 3.0000 |
| Age | 332.0 | 30.272590 | 14.181209 | 0.17 | 21.0000 | 27.0000 | 39.00 | 76.0000 |
| SibSp | 418.0 | 0.447368 | 0.896760 | 0.00 | 0.0000 | 0.0000 | 1.00 | 8.0000 |
| Parch | 418.0 | 0.392344 | 0.981429 | 0.00 | 0.0000 | 0.0000 | 0.00 | 9.0000 |
| Fare | 417.0 | 35.627188 | 55.907576 | 0.00 | 7.8958 | 14.4542 | 31.50 | 512.3292 |
display(df_train.describe(include='object').T, df_test.describe(include='object').T)| count | unique | top | freq | |
|---|---|---|---|---|
| Name | 891 | 891 | Braund, Mr. Owen Harris | 1 |
| Sex | 891 | 2 | male | 577 |
| Ticket | 891 | 681 | 347082 | 7 |
| Cabin | 204 | 147 | B96 B98 | 4 |
| Embarked | 889 | 3 | S | 644 |
| count | unique | top | freq | |
|---|---|---|---|---|
| Name | 418 | 418 | Kelly, Mr. James | 1 |
| Sex | 418 | 2 | male | 266 |
| Ticket | 418 | 363 | PC 17608 | 5 |
| Cabin | 91 | 76 | B57 B59 B63 B66 | 3 |
| Embarked | 418 | 3 | S | 270 |
display(df_train['Cabin'].str[0], df_train['Cabin'].str[1:])0 NaN
1 C
2 NaN
3 C
4 NaN
...
886 NaN
887 B
888 NaN
889 C
890 NaN
Name: Cabin, Length: 891, dtype: object0 NaN
1 85
2 NaN
3 123
4 NaN
...
886 NaN
887 42
888 NaN
889 148
890 NaN
Name: Cabin, Length: 891, dtype: object[i.rsplit(" ", -1) for i in df_train['Ticket'].tolist()[:5]][['A/5', '21171'],
['PC', '17599'],
['STON/O2.', '3101282'],
['113803'],
['373450']]def get_ticket_features(row):
if len(row) == 2: return [row[0], int(row[1])]
else:
if row[0].isdigit(): return [pd.NA, int(row[0])]
else: return [row[0], pd.NA]
def expand_ticket(X):
s = X.squeeze().str.rsplit(" ").apply(get_ticket_features)
df = pd.DataFrame(s.tolist(), columns=['prefix_ticket', 'num_ticket'])
return df
# def split_col(X, splitter=" "): return X.squeeze().str.split(splitter, expand=True).apply(pd.to_numeric, errors='ignore', downcast='integer')
# split_col(df_train[['Ticket']], splitter=' ')
# expand_ticket(df_train[['Ticket']])
ticket_transformer = ColExpanderTransform(names=['prefix_ticket', 'num_ticket'], func=expand_ticket, func_kw_args={})
display(ticket_transformer.fit_transform(df_train[['Ticket']]), ticket_transformer.get_feature_names())| prefix_ticket | num_ticket | |
|---|---|---|
| 0 | A/5 | 21171 |
| 1 | PC | 17599 |
| 2 | STON/O2. | 3101282 |
| 3 | <NA> | 113803 |
| 4 | <NA> | 373450 |
| ... | ... | ... |
| 886 | <NA> | 211536 |
| 887 | <NA> | 112053 |
| 888 | W./C. | 6607 |
| 889 | <NA> | 111369 |
| 890 | <NA> | 370376 |
891 rows × 2 columns
['prefix_ticket', 'num_ticket']df_train['Name'][1]'Cumings, Mrs. John Bradley (Florence Briggs Thayer)'feature_specs = {
'Ticket':(ColExpanderTransform, {'names':['prefix_ticket', 'num_ticket'], 'func':expand_ticket, 'func_kw_args':{}}),
}
gen_feature_layer(df_train, feature_specs)[('Ticket', <aiking.ml.structured.ColExpanderTransform>, {}),
('PassengerId', None),
('Survived', None),
('Pclass', None),
('Name', None),
('Sex', None),
('Age', None),
('SibSp', None),
('Parch', None),
('Fare', None),
('Cabin', None),
('Embarked', None)]Modelling
Define Pipeline
def get_model_pipeline(max_n_cat=0,
cat_dict=None,
scale_dict={'class': StandardScaler},
cat_num_dict={'class':NumericalEncoder,'categories':None},
cat_dummy_dict={'class':OneHotEncoder,'handle_unknown':'ignore'},
imputer_dict={'class':SimpleImputer, 'strategy':'median'},
):
layer_spec_preprocess = (gen_feature_layer,
{
'feature_specs':{
'Ticket':(ColExpanderTransform, {'names':['prefix_ticket', 'num_ticket'], 'func':expand_ticket, 'func_kw_args':{}}),
}
})
layer_spec_default = (get_default_feature_def,
{
'skip_flds':None,
'ignored_flds':None,
'max_n_cat':max_n_cat,
'na_exclude_cols':[],
'scale_var_num':True,
'scale_var_cat':False,
'scale_dict':scale_dict,
'cat_num_dict':cat_num_dict,
'cat_dummy_dict':cat_dummy_dict,
'imputer_dict':imputer_dict,
'include_time_cols':True,
'keep_dt_cols':False,
'cat_dict':cat_dict
}
)
layer_specs = [layer_spec_preprocess, layer_spec_default]
proc = Proc(layer_specs=layer_specs); #proc.fit_transform(X)
model = RandomForestClassifier(oob_score=True, n_jobs=-1)
pipeline = make_pipeline(proc, model); pipeline
return pipelinepipeline = get_model_pipeline(cat_dict=None); pipelinePipeline(steps=[('proc', <aiking.ml.structured.Proc object at 0x2927bae80>),
('randomforestclassifier',
RandomForestClassifier(n_jobs=-1, oob_score=True))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('proc', <aiking.ml.structured.Proc object at 0x2927bae80>),
('randomforestclassifier',
RandomForestClassifier(n_jobs=-1, oob_score=True))])<aiking.ml.structured.Proc object at 0x2927bae80>
RandomForestClassifier(n_jobs=-1, oob_score=True)
Train on Partial Data
max_n_cat = 5
def get_xy(df, col='Survived'): return df.drop([col], axis=1), df[col]
X, y = get_xy(df_train)
pipeline = get_model_pipeline(max_n_cat,cat_dict=None)
pipeline.fit(X, y)Pipeline(steps=[('proc', <aiking.ml.structured.Proc object at 0x29356ff40>),
('randomforestclassifier',
RandomForestClassifier(n_jobs=-1, oob_score=True))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('proc', <aiking.ml.structured.Proc object at 0x29356ff40>),
('randomforestclassifier',
RandomForestClassifier(n_jobs=-1, oob_score=True))])<aiking.ml.structured.Proc object at 0x29356ff40>
RandomForestClassifier(n_jobs=-1, oob_score=True)
get_scorer_dict(scorer_names=['accuracy', 'precision', 'recall', 'roc_auc']){'accuracy': make_scorer(accuracy_score),
'precision': make_scorer(precision_score, average=binary),
'recall': make_scorer(recall_score, average=binary),
'roc_auc': make_scorer(roc_auc_score, needs_threshold=True)}This gives an indication of estimate of msle around .26 to .30[Really 0.304 from validation estimate]
m = pipeline['randomforestclassifier']
m.oob_score_0.8372615039281706Cross validation estimate
pipeline = get_model_pipeline(max_n_cat,cat_dict=None)
# scores = cross_val_score(pipeline, X, y, scoring='accuracy'); scores
scores_df = pd.DataFrame(cross_validate(pipeline, X, y,
scoring=['accuracy', 'precision', 'recall', 'roc_auc'],
return_train_score=True)); scores_df| fit_time | score_time | test_accuracy | train_accuracy | test_precision | train_precision | test_recall | train_recall | test_roc_auc | train_roc_auc | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.506517 | 0.046242 | 0.737430 | 1.0 | 0.739130 | 1.0 | 0.492754 | 1.0 | 0.837022 | 1.0 |
| 1 | 0.084883 | 0.039459 | 0.797753 | 1.0 | 0.735294 | 1.0 | 0.735294 | 1.0 | 0.805548 | 1.0 |
| 2 | 0.085794 | 0.038840 | 0.842697 | 1.0 | 0.785714 | 1.0 | 0.808824 | 1.0 | 0.917647 | 1.0 |
| 3 | 0.087844 | 0.038950 | 0.808989 | 1.0 | 0.814815 | 1.0 | 0.647059 | 1.0 | 0.888971 | 1.0 |
| 4 | 0.087772 | 0.038551 | 0.837079 | 1.0 | 0.803030 | 1.0 | 0.768116 | 1.0 | 0.881000 | 1.0 |
# m = pipeline['randomforestclassifier']
cv_scores = cross_val_score(pipeline, X, y, cv=5)
cv_scoresarray([0.83798883, 0.79213483, 0.87640449, 0.82022472, 0.86516854])scores_df.plot()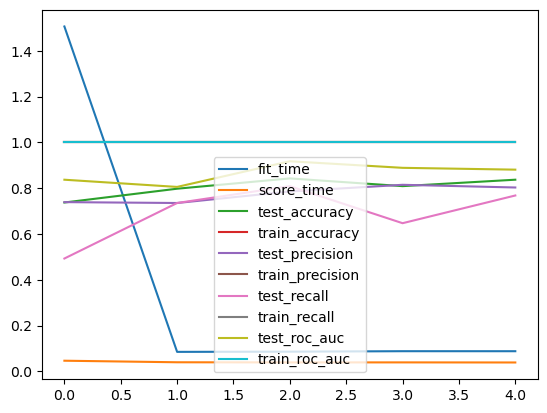
# pipeline = get_model_pipeline(cat_dict); pipeline
y_pred = cross_val_predict(pipeline, X, y)
# cm = confusion_matrix(y, y_pred)
# disp = ConfusionMatrixDisplay(confusion_matrix=cm)
# disp.plot()
ConfusionMatrixDisplay.from_predictions(y, y_pred)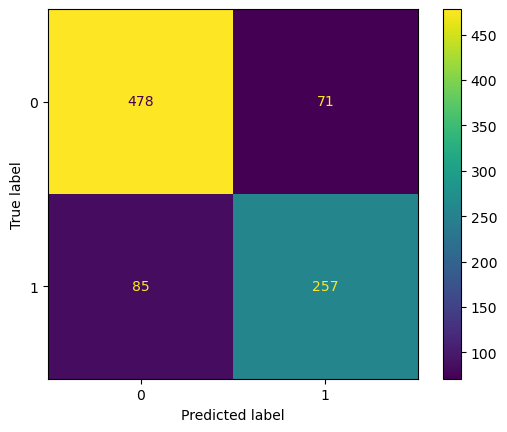
scores = scores_df['test_accuracy']
print(f"Expected Scores {scores.mean() - 3*scores.std():.2%} to {scores.mean() + 3*scores.std():.2%} with mean as {scores.mean():.2%}")Expected Scores 67.85% to 93.10% with mean as 80.48%Single tree model
max_n_cat = 5
def get_model_pipeline2(model, max_n_cat=0,
cat_dict=None,
scale_dict={'class': StandardScaler},
cat_num_dict={'class':NumericalEncoder,'categories':None},
cat_dummy_dict={'class':OneHotEncoder,'handle_unknown':'ignore'},
imputer_dict={'class':SimpleImputer, 'strategy':'median'},
):
layer_spec_preprocess = (gen_feature_layer,
{
'feature_specs':{
'Ticket':(ColExpanderTransform, {'names':['prefix_ticket', 'num_ticket'], 'func':expand_ticket, 'func_kw_args':{}}),
}
})
layer_spec_default = (get_default_feature_def,
{
'skip_flds':None,
'ignored_flds':None,
'max_n_cat':max_n_cat,
'na_exclude_cols':[],
'scale_var_num':True,
'scale_var_cat':False,
'scale_dict':scale_dict,
'cat_num_dict':cat_num_dict,
'cat_dummy_dict':cat_dummy_dict,
'imputer_dict':imputer_dict,
'include_time_cols':True,
'keep_dt_cols':False,
'cat_dict':cat_dict
}
)
layer_specs = [layer_spec_preprocess, layer_spec_default]
proc = Proc(layer_specs=layer_specs); #proc.fit_transform(X)
model = model
pipeline = make_pipeline(proc, model); pipeline
return pipeline
def get_xy(df, col='Survived'): return df.drop([col], axis=1), df[col]
X, y = get_xy(df_train)
model = RandomForestClassifier(n_estimators=1, bootstrap=False, max_depth=3, oob_score=False, n_jobs=-1)
pipeline2 = get_model_pipeline2(model, max_n_cat,cat_dict=None)
pipeline2.fit(X, y)Pipeline(steps=[('proc', <aiking.ml.structured.Proc object at 0x2a25fb850>),
('randomforestclassifier',
RandomForestClassifier(bootstrap=False, max_depth=3,
n_estimators=1, n_jobs=-1))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('proc', <aiking.ml.structured.Proc object at 0x2a25fb850>),
('randomforestclassifier',
RandomForestClassifier(bootstrap=False, max_depth=3,
n_estimators=1, n_jobs=-1))])<aiking.ml.structured.Proc object at 0x2a25fb850>
RandomForestClassifier(bootstrap=False, max_depth=3, n_estimators=1, n_jobs=-1)
pipeline2 = get_model_pipeline2(model, max_n_cat,cat_dict=None)
X, y = get_xy(df_train)
scores_df = pd.DataFrame(cross_validate(pipeline2, X, y,
scoring=['accuracy', 'precision', 'recall', 'roc_auc'],
return_train_score=True)); scores_df| fit_time | score_time | test_accuracy | train_accuracy | test_precision | train_precision | test_recall | train_recall | test_roc_auc | train_roc_auc | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.039830 | 0.025932 | 0.759777 | 0.800562 | 0.964286 | 0.945578 | 0.391304 | 0.509158 | 0.829117 | 0.832578 |
| 1 | 0.034812 | 0.024542 | 0.679775 | 0.730715 | 0.720000 | 0.741176 | 0.264706 | 0.459854 | 0.624733 | 0.749077 |
| 2 | 0.036440 | 0.025795 | 0.730337 | 0.812062 | 0.604167 | 0.751799 | 0.852941 | 0.762774 | 0.838770 | 0.851728 |
| 3 | 0.034458 | 0.024143 | 0.769663 | 0.823282 | 0.754717 | 0.780303 | 0.588235 | 0.751825 | 0.849799 | 0.862295 |
| 4 | 0.036281 | 0.025915 | 0.797753 | 0.799439 | 0.789474 | 0.773109 | 0.652174 | 0.673993 | 0.806010 | 0.833879 |
pipeline2['proc'].fit_transform(X)| Ticket_prefix_ticket_nan | Ticket_num_ticket_nan | Age_nan | Cabin_nan | Ticket_prefix_ticket | Ticket_num_ticket | Name | Cabin | Sex_0 | Sex_1 | Embarked_0 | Embarked_1 | Embarked_2 | Embarked_3 | PassengerId | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | False | False | True | 5 | 225 | 109 | 0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | -1.730108 | 0.827377 | -0.565736 | 0.432793 | -0.473674 | -0.502445 |
| 1 | False | False | False | False | 19 | 193 | 191 | 82 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | -1.726220 | -1.566107 | 0.663861 | 0.432793 | -0.473674 | 0.786845 |
| 2 | False | False | False | True | 38 | 651 | 354 | 0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | -1.722332 | 0.827377 | -0.258337 | -0.474545 | -0.473674 | -0.488854 |
| 3 | True | False | False | False | 0 | 348 | 273 | 56 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | -1.718444 | -1.566107 | 0.433312 | 0.432793 | -0.473674 | 0.420730 |
| 4 | True | False | False | True | 0 | 618 | 16 | 0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | -1.714556 | 0.827377 | 0.433312 | -0.474545 | -0.473674 | -0.486337 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | True | False | False | True | 0 | 352 | 549 | 0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.714556 | -0.369365 | -0.181487 | -0.474545 | -0.473674 | -0.386671 |
| 887 | True | False | False | False | 0 | 313 | 304 | 31 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.718444 | -1.566107 | -0.796286 | -0.474545 | -0.473674 | -0.044381 |
| 888 | False | False | True | True | 40 | 106 | 414 | 0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.722332 | 0.827377 | -0.104637 | 0.432793 | 2.008933 | -0.176263 |
| 889 | True | False | False | False | 0 | 307 | 82 | 61 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.726220 | -1.566107 | -0.258337 | -0.474545 | -0.473674 | -0.044381 |
| 890 | True | False | False | True | 0 | 612 | 221 | 0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.730108 | 0.827377 | 0.202762 | -0.474545 | -0.473674 | -0.492378 |
891 rows × 20 columns
X| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Thayer) | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 887 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S |
| 887 | 888 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S |
| 888 | 889 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S |
| 889 | 890 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C |
| 890 | 891 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q |
891 rows × 11 columns
scores_df.mean()fit_time 0.036364
score_time 0.025265
test_accuracy 0.747461
train_accuracy 0.793212
test_precision 0.766529
train_precision 0.798393
test_recall 0.549872
train_recall 0.631521
test_roc_auc 0.789686
train_roc_auc 0.825911
dtype: float64pipeline2['proc'].transform(X)| Ticket_prefix_ticket_nan | Ticket_num_ticket_nan | Age_nan | Cabin_nan | Ticket_prefix_ticket | Ticket_num_ticket | Name | Cabin | Sex_0 | Sex_1 | Embarked_0 | Embarked_1 | Embarked_2 | Embarked_3 | PassengerId | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | False | False | True | 5 | 225 | 109 | 0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | -1.730108 | 0.827377 | -0.565736 | 0.432793 | -0.473674 | -0.502445 |
| 1 | False | False | False | False | 19 | 193 | 191 | 82 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | -1.726220 | -1.566107 | 0.663861 | 0.432793 | -0.473674 | 0.786845 |
| 2 | False | False | False | True | 38 | 651 | 354 | 0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | -1.722332 | 0.827377 | -0.258337 | -0.474545 | -0.473674 | -0.488854 |
| 3 | True | False | False | False | 0 | 348 | 273 | 56 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | -1.718444 | -1.566107 | 0.433312 | 0.432793 | -0.473674 | 0.420730 |
| 4 | True | False | False | True | 0 | 618 | 16 | 0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | -1.714556 | 0.827377 | 0.433312 | -0.474545 | -0.473674 | -0.486337 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | True | False | False | True | 0 | 352 | 549 | 0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.714556 | -0.369365 | -0.181487 | -0.474545 | -0.473674 | -0.386671 |
| 887 | True | False | False | False | 0 | 313 | 304 | 31 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.718444 | -1.566107 | -0.796286 | -0.474545 | -0.473674 | -0.044381 |
| 888 | False | False | True | True | 40 | 106 | 414 | 0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.722332 | 0.827377 | -0.104637 | 0.432793 | 2.008933 | -0.176263 |
| 889 | True | False | False | False | 0 | 307 | 82 | 61 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.726220 | -1.566107 | -0.258337 | -0.474545 | -0.473674 | -0.044381 |
| 890 | True | False | False | True | 0 | 612 | 221 | 0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.730108 | 0.827377 | 0.202762 | -0.474545 | -0.473674 | -0.492378 |
891 rows × 20 columns
feature_names = pipeline2['proc'].transform(X).columns.tolist(); feature_names['Ticket_prefix_ticket_nan',
'Ticket_num_ticket_nan',
'Age_nan',
'Cabin_nan',
'Ticket_prefix_ticket',
'Ticket_num_ticket',
'Name',
'Cabin',
'Sex_0',
'Sex_1',
'Embarked_0',
'Embarked_1',
'Embarked_2',
'Embarked_3',
'PassengerId',
'Pclass',
'Age',
'SibSp',
'Parch',
'Fare']from sklearn import tree
# tree.plot_tree(model.estimators_[0], filled=True, feature_names=feature_names, fontsize=8);
# tree.plot_tree?# pipeline2 = get_model_pipeline2(model, max_n_cat,cat_dict=None)
pipeline2['proc'].transform(X).head().T| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| Ticket_prefix_ticket_nan | False | False | False | True | True |
| Ticket_num_ticket_nan | False | False | False | False | False |
| Age_nan | False | False | False | False | False |
| Cabin_nan | True | False | True | False | True |
| Ticket_prefix_ticket | 5 | 19 | 38 | 0 | 0 |
| Ticket_num_ticket | 225 | 193 | 651 | 348 | 618 |
| Name | 109 | 191 | 354 | 273 | 16 |
| Cabin | 0 | 82 | 0 | 56 | 0 |
| Sex_0 | 0.0 | 1.0 | 1.0 | 1.0 | 0.0 |
| Sex_1 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| Embarked_0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| Embarked_1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Embarked_2 | 1.0 | 0.0 | 1.0 | 1.0 | 1.0 |
| Embarked_3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| PassengerId | -1.730108 | -1.72622 | -1.722332 | -1.718444 | -1.714556 |
| Pclass | 0.827377 | -1.566107 | 0.827377 | -1.566107 | 0.827377 |
| Age | -0.565736 | 0.663861 | -0.258337 | 0.433312 | 0.433312 |
| SibSp | 0.432793 | 0.432793 | -0.474545 | 0.432793 | -0.474545 |
| Parch | -0.473674 | -0.473674 | -0.473674 | -0.473674 | -0.473674 |
| Fare | -0.502445 | 0.786845 | -0.488854 | 0.42073 | -0.486337 |
from sklearn.tree import export_graphviz
import IPython, graphviz
def draw_tree(t, df, size=10, ratio=0.6, precision=3):
"""Draws a representation of a random forest in IPython."""
s=export_graphviz(t, out_file=None, feature_names=df.columns, filled=True,
special_characters=True, rotate=True, precision=precision)
IPython.display.display(graphviz.Source(re.sub('Tree {',
f'Tree {{ size={size}; ratio={ratio}', s)))
draw_tree(model.estimators_[0], pipeline2['proc'].transform(X))
Deep Tree
model2 = RandomForestClassifier(n_estimators=1, bootstrap=False, oob_score=False, n_jobs=-1)
pipeline3 = get_model_pipeline2(model2, max_n_cat,cat_dict=None)
X, y = get_xy(df_train)
scores_df = pd.DataFrame(cross_validate(pipeline2, X, y,
scoring=['accuracy', 'precision', 'recall', 'roc_auc'],
return_train_score=True)); scores_df.mean()fit_time 0.056928
score_time 0.030233
test_accuracy 0.788984
train_accuracy 0.800229
test_precision 0.816734
train_precision 0.820361
test_recall 0.596462
train_recall 0.629440
test_roc_auc 0.776113
train_roc_auc 0.840716
dtype: float64X, y = get_xy(df_train)
pipeline3 = get_model_pipeline2(model2, max_n_cat,cat_dict=None)
pipeline3.fit(X, y)Pipeline(steps=[('proc', <aiking.ml.structured.Proc object at 0x2a10a9550>),
('randomforestclassifier',
RandomForestClassifier(bootstrap=False, n_estimators=1,
n_jobs=-1))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('proc', <aiking.ml.structured.Proc object at 0x2a10a9550>),
('randomforestclassifier',
RandomForestClassifier(bootstrap=False, n_estimators=1,
n_jobs=-1))])<aiking.ml.structured.Proc object at 0x2a10a9550>
RandomForestClassifier(bootstrap=False, n_estimators=1, n_jobs=-1)
pipeline3['proc'].transform(X)| Ticket_prefix_ticket_nan | Ticket_num_ticket_nan | Age_nan | Cabin_nan | Ticket_prefix_ticket | Ticket_num_ticket | Name | Cabin | Sex_0 | Sex_1 | Embarked_0 | Embarked_1 | Embarked_2 | Embarked_3 | PassengerId | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | False | False | True | 5 | 225 | 109 | 0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | -1.730108 | 0.827377 | -0.565736 | 0.432793 | -0.473674 | -0.502445 |
| 1 | False | False | False | False | 19 | 193 | 191 | 82 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | -1.726220 | -1.566107 | 0.663861 | 0.432793 | -0.473674 | 0.786845 |
| 2 | False | False | False | True | 38 | 651 | 354 | 0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | -1.722332 | 0.827377 | -0.258337 | -0.474545 | -0.473674 | -0.488854 |
| 3 | True | False | False | False | 0 | 348 | 273 | 56 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | -1.718444 | -1.566107 | 0.433312 | 0.432793 | -0.473674 | 0.420730 |
| 4 | True | False | False | True | 0 | 618 | 16 | 0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | -1.714556 | 0.827377 | 0.433312 | -0.474545 | -0.473674 | -0.486337 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | True | False | False | True | 0 | 352 | 549 | 0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.714556 | -0.369365 | -0.181487 | -0.474545 | -0.473674 | -0.386671 |
| 887 | True | False | False | False | 0 | 313 | 304 | 31 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.718444 | -1.566107 | -0.796286 | -0.474545 | -0.473674 | -0.044381 |
| 888 | False | False | True | True | 40 | 106 | 414 | 0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.722332 | 0.827377 | -0.104637 | 0.432793 | 2.008933 | -0.176263 |
| 889 | True | False | False | False | 0 | 307 | 82 | 61 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.726220 | -1.566107 | -0.258337 | -0.474545 | -0.473674 | -0.044381 |
| 890 | True | False | False | True | 0 | 612 | 221 | 0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.730108 | 0.827377 | 0.202762 | -0.474545 | -0.473674 | -0.492378 |
891 rows × 20 columns
draw_tree(model2.estimators_[0], pipeline3['proc'].transform(X))
Multiple Estimators
model3 = RandomForestClassifier(oob_score=True, n_jobs=-1, max_depth=3)
pipeline3 = get_model_pipeline2(model3, max_n_cat,cat_dict=None)
X, y = get_xy(df_train)
scores_df = pd.DataFrame(cross_validate(pipeline2, X, y,
scoring=['accuracy', 'precision', 'recall', 'roc_auc'],
return_train_score=True)); scores_df.mean()fit_time 0.037160
score_time 0.024400
test_accuracy 0.753079
train_accuracy 0.768236
test_precision 0.723124
train_precision 0.737067
test_recall 0.614450
train_recall 0.625572
test_roc_auc 0.793409
train_roc_auc 0.798709
dtype: float64X, y = get_xy(df_train)
pipeline3 = get_model_pipeline2(model3, max_n_cat,cat_dict=None)
pipeline3.fit(X, y)Pipeline(steps=[('proc', <aiking.ml.structured.Proc object at 0x2a113f6a0>),
('randomforestclassifier',
RandomForestClassifier(max_depth=3, n_jobs=-1,
oob_score=True))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('proc', <aiking.ml.structured.Proc object at 0x2a113f6a0>),
('randomforestclassifier',
RandomForestClassifier(max_depth=3, n_jobs=-1,
oob_score=True))])<aiking.ml.structured.Proc object at 0x2a113f6a0>
RandomForestClassifier(max_depth=3, n_jobs=-1, oob_score=True)
draw_tree(model3.estimators_[0], pipeline3['proc'].transform(X))
preds = np.stack([t.predict(pipeline3['proc'].transform(X)) for t in model3.estimators_])
preds[:,0],np.mean(preds[:,0]), y[0](array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]),
0.0,
0)Predictions
Retrain pipeline on complete dataset
pipeline = get_model_pipeline(max_n_cat,cat_dict=None)
pipeline.fit(X, y)
y_pred = pipeline.predict(X)
cm = confusion_matrix(y, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm)
display(disp.plot(), accuracy_score(y, y_pred))<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay>1.0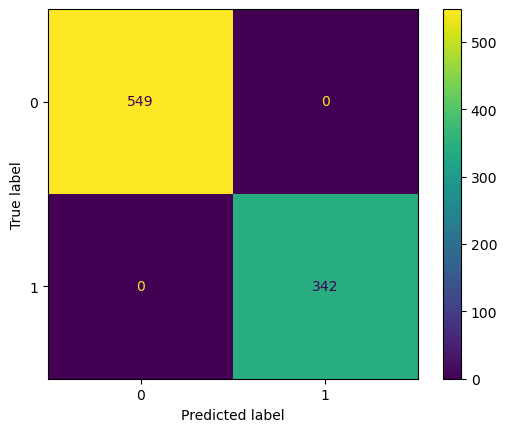
Calculation for test set and submission
df_sample_submission = pd.read_csv(path/"gender_submission.csv"); df_sample_submission.head()| PassengerId | Survived | |
|---|---|---|
| 0 | 892 | 0 |
| 1 | 893 | 1 |
| 2 | 894 | 0 |
| 3 | 895 | 0 |
| 4 | 896 | 1 |
os.getcwd()'/Users/rahul1.saraf/rahuketu/programming/portfolio/curations/competitions/titanic'predictions = pd.DataFrame(pipeline.predict(df_test), columns=[y.squeeze().name]); predictions
df_submission = pd.concat([df_test['PassengerId'], predictions], axis=1); df_submission
df_submission.to_csv('submission.csv', index=False)if not is_kaggle:
import kaggle
kaggle.api.competition_submit_cli("submission.csv", "Submission from local machine", competition="titanic")
# from aiking.integrations.kaggle import push2kaggle
# push2kaggle("00_index.ipynb")Warning: Looks like you're using an outdated API Version, please consider updating (server 1.6.12 / client 1.5.16)100%|██████████████████████████████████████| 2.77k/2.77k [00:02<00:00, 1.32kB/s]