import fastcore
import pandas as pd
import pathlib
from fastcore.all import *
from fastcore.imports import *
import os
import sys
import sklearn
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score, cross_val_predict, KFold, train_test_split, cross_validate
from sklearn.metrics import ConfusionMatrixDisplay, accuracy_score, confusion_matrix
from IPython.display import display
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoderImport public packages
Import private packages
is_kaggle = 'kaggle_secrets' in sys.modulesif is_kaggle:
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
os.environ['KAGGLE_USERNAME'] = user_secrets.get_secret("kaggle_username")
if not os.environ['KAGGLE_USERNAME']: raise Exception("Please insert your Kaggle username and key into Kaggle secrets")
os.environ['KAGGLE_KEY'] = user_secrets.get_secret("kaggle_key")
github_pat = user_secrets.get_secret("GITHUB_PAT")
!pip install -Uqq git+https://{github_pat}@github.com/Rahuketu86/aiking
else:
from aiking.data.external import *
path = untar_data("kaggle_competitions::titanic");
print(path.ls())[Path('/Users/rahul1.saraf/rahuketu/programming/AIKING_HOME/data/titanic/test.csv'), Path('/Users/rahul1.saraf/rahuketu/programming/AIKING_HOME/data/titanic/train.csv'), Path('/Users/rahul1.saraf/rahuketu/programming/AIKING_HOME/data/titanic/gender_submission.csv')]from aiking.ml.structured import *Read the Dataset
data_dir = pathlib.Path(os.getenv('DATA_DIR', "/kaggle/input"));
path = data_dir/"titanic"
path.ls()(#3) [Path('/Users/rahul1.saraf/rahuketu/programming/AIKING_HOME/data/titanic/test.csv'),Path('/Users/rahul1.saraf/rahuketu/programming/AIKING_HOME/data/titanic/train.csv'),Path('/Users/rahul1.saraf/rahuketu/programming/AIKING_HOME/data/titanic/gender_submission.csv')]df_train = pd.read_csv(path/"train.csv"); df_train.head()
df_test = pd.read_csv(path/"test.csv"); df_test.head()| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | Kelly, Mr. James | male | 34.5 | 0 | 0 | 330911 | 7.8292 | NaN | Q |
| 1 | 893 | 3 | Wilkes, Mrs. James (Ellen Needs) | female | 47.0 | 1 | 0 | 363272 | 7.0000 | NaN | S |
| 2 | 894 | 2 | Myles, Mr. Thomas Francis | male | 62.0 | 0 | 0 | 240276 | 9.6875 | NaN | Q |
| 3 | 895 | 3 | Wirz, Mr. Albert | male | 27.0 | 0 | 0 | 315154 | 8.6625 | NaN | S |
| 4 | 896 | 3 | Hirvonen, Mrs. Alexander (Helga E Lindqvist) | female | 22.0 | 1 | 1 | 3101298 | 12.2875 | NaN | S |
df_train.describe(include='all').T| count | unique | top | freq | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | 891.0 | NaN | NaN | NaN | 446.0 | 257.353842 | 1.0 | 223.5 | 446.0 | 668.5 | 891.0 |
| Survived | 891.0 | NaN | NaN | NaN | 0.383838 | 0.486592 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 |
| Pclass | 891.0 | NaN | NaN | NaN | 2.308642 | 0.836071 | 1.0 | 2.0 | 3.0 | 3.0 | 3.0 |
| Name | 891 | 891 | Braund, Mr. Owen Harris | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Sex | 891 | 2 | male | 577 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Age | 714.0 | NaN | NaN | NaN | 29.699118 | 14.526497 | 0.42 | 20.125 | 28.0 | 38.0 | 80.0 |
| SibSp | 891.0 | NaN | NaN | NaN | 0.523008 | 1.102743 | 0.0 | 0.0 | 0.0 | 1.0 | 8.0 |
| Parch | 891.0 | NaN | NaN | NaN | 0.381594 | 0.806057 | 0.0 | 0.0 | 0.0 | 0.0 | 6.0 |
| Ticket | 891 | 681 | 347082 | 7 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Fare | 891.0 | NaN | NaN | NaN | 32.204208 | 49.693429 | 0.0 | 7.9104 | 14.4542 | 31.0 | 512.3292 |
| Cabin | 204 | 147 | B96 B98 | 4 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Embarked | 889 | 3 | S | 644 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
Modelling
Define Pipeline
def get_model_pipeline(max_n_cat=0,
cat_dict=None,
scale_dict={'class': StandardScaler},
cat_num_dict={'class':NumericalEncoder,'categories':None},
cat_dummy_dict={'class':OneHotEncoder,'handle_unknown':'ignore'},
imputer_dict={'class':SimpleImputer, 'strategy':'median'},
):
layer_spec_default = (get_default_feature_def,
{
'skip_flds':None,
'ignored_flds':None,
'max_n_cat':max_n_cat,
'na_exclude_cols':[],
'scale_var_num':True,
'scale_var_cat':False,
'scale_dict':scale_dict,
'cat_num_dict':cat_num_dict,
'cat_dummy_dict':cat_dummy_dict,
'imputer_dict':imputer_dict,
'include_time_cols':True,
'keep_dt_cols':False,
'cat_dict':cat_dict
}
)
layer_specs = [layer_spec_default]
proc = Proc(layer_specs=layer_specs); #proc.fit_transform(X)
model = RandomForestClassifier(n_jobs=-1)
pipeline = make_pipeline(proc, model); pipeline
return pipelinepipeline = get_model_pipeline(cat_dict=None); pipelinePipeline(steps=[('proc', <aiking.ml.structured.Proc object at 0x155257070>),
('randomforestclassifier', RandomForestClassifier(n_jobs=-1))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('proc', <aiking.ml.structured.Proc object at 0x155257070>),
('randomforestclassifier', RandomForestClassifier(n_jobs=-1))])<aiking.ml.structured.Proc object at 0x155257070>
RandomForestClassifier(n_jobs=-1)
Train on Partial Data
max_n_cat = 5
def get_xy(df, col='Survived'): return df.drop([col], axis=1), df[col]
X, y = get_xy(df_train)
pipeline = get_model_pipeline(max_n_cat,cat_dict=None)
pipeline.fit(X, y)Pipeline(steps=[('proc', <aiking.ml.structured.Proc object at 0x155257c40>),
('randomforestclassifier', RandomForestClassifier(n_jobs=-1))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('proc', <aiking.ml.structured.Proc object at 0x155257c40>),
('randomforestclassifier', RandomForestClassifier(n_jobs=-1))])<aiking.ml.structured.Proc object at 0x155257c40>
RandomForestClassifier(n_jobs=-1)
get_scorer_dict(scorer_names=['accuracy', 'precision', 'recall', 'roc_auc']){'accuracy': make_scorer(accuracy_score),
'precision': make_scorer(precision_score, average=binary),
'recall': make_scorer(recall_score, average=binary),
'roc_auc': make_scorer(roc_auc_score, needs_threshold=True)}This gives an indication of estimate of msle around .26 to .30[Really 0.304 from validation estimate]
Cross validation estimate
pipeline = get_model_pipeline(max_n_cat,cat_dict=None)
# scores = cross_val_score(pipeline, X, y, scoring='accuracy'); scores
scores_df = pd.DataFrame(cross_validate(pipeline, X, y, scoring=['accuracy', 'precision', 'recall', 'roc_auc'])); scores_df| fit_time | score_time | test_accuracy | test_precision | test_recall | test_roc_auc | |
|---|---|---|---|---|---|---|
| 0 | 1.532780 | 0.041193 | 0.776536 | 0.737705 | 0.652174 | 0.830303 |
| 1 | 0.068360 | 0.036002 | 0.747191 | 0.641975 | 0.764706 | 0.808690 |
| 2 | 0.063332 | 0.034494 | 0.792135 | 0.674157 | 0.882353 | 0.902473 |
| 3 | 0.063486 | 0.035383 | 0.814607 | 0.786885 | 0.705882 | 0.867112 |
| 4 | 0.060760 | 0.037809 | 0.808989 | 0.716049 | 0.840580 | 0.892833 |
scores_df.plot()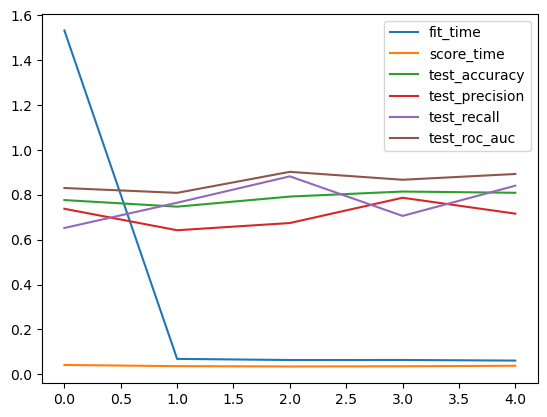
# pipeline = get_model_pipeline(cat_dict); pipeline
y_pred = cross_val_predict(pipeline, X, y)
# cm = confusion_matrix(y, y_pred)
# disp = ConfusionMatrixDisplay(confusion_matrix=cm)
# disp.plot()
ConfusionMatrixDisplay.from_predictions(y, y_pred)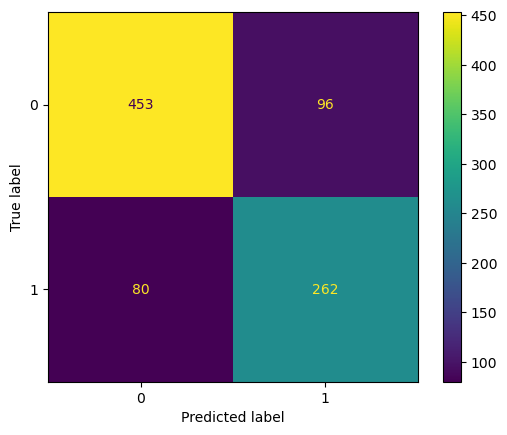
scores = scores_df['test_accuracy']
print(f"Expected Scores {scores.mean() - 3*scores.std():.2%} to {scores.mean() + 3*scores.std():.2%} with mean as {scores.mean():.2%}")Expected Scores 70.63% to 86.95% with mean as 78.79%Predictions
Retrain pipeline on complete dataset
pipeline = get_model_pipeline(max_n_cat,cat_dict=None)
pipeline.fit(X, y)
y_pred = pipeline.predict(X)
cm = confusion_matrix(y, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm)
display(disp.plot(), accuracy_score(y, y_pred))<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay>1.0
Calculation for test set and submission
df_sample_submission = pd.read_csv(path/"gender_submission.csv"); df_sample_submission.head()| PassengerId | Survived | |
|---|---|---|
| 0 | 892 | 0 |
| 1 | 893 | 1 |
| 2 | 894 | 0 |
| 3 | 895 | 0 |
| 4 | 896 | 1 |
os.getcwd()'/Users/rahul1.saraf/rahuketu/programming/portfolio/curations/competitions/titanic'predictions = pd.DataFrame(pipeline.predict(df_test), columns=[y.squeeze().name]); predictions
df_submission = pd.concat([df_test['PassengerId'], predictions], axis=1); df_submission
df_submission.to_csv('submission.csv', index=False)if not is_kaggle:
import kaggle
kaggle.api.competition_submit_cli("submission.csv", "Submission from local machine", competition="titanic")
# from aiking.integrations.kaggle import push2kaggle
# push2kaggle("00_index.ipynb")Warning: Looks like you're using an outdated API Version, please consider updating (server 1.6.12 / client 1.5.16)100%|██████████████████████████████████████| 2.77k/2.77k [00:01<00:00, 1.77kB/s]