from fastai.vision.all import *
from fastcore.all import *
from functools import partial
import warnings
import panel as pn![]()
Compatibility Block
Check Platform
Platform & Environment Configuration
Imports
Public Imports
pn.extension(design='material')
warnings.filterwarnings("ignore")Private Imports
from aiking.data.external import *
from aiking.core import aiking_settings
from aiking.integrations.datasette import *
from aiking.dl.widgets import PersistentImageClassifierCleaner
from aiking.dl.panelwidgets import PanelImageClassifierCleanerPandemic Safety
Our dataset consist of images labelled as mask or no_mask. We will do following steps
- Build a classifier on raw version of data
- Review images with highest confusion. Identify images we would, like to keep, relabel or skip
dsname = 'PandemicSafety'
datasette_base_url = "https://datasette.zealmaker.com"path = data_frm_datasette(dsname, datasette_base_url); pathPath('/mnt/d/rahuketu/programming/AIKING_HOME/data/PandemicSafety')DataBlocks and DataLoaders
In present example, I will use image.csv to generate items and labels. Advantages are:-
- I don’t have to delete any file
- I can manage modifications to dataset in a new csv file and upload the version on Datasette for future review
- dataloaders has a path argument. To be consistent with fastai dataloader we need to supply path for df execution
We will get list of fnames and labels from dataframe. If we require cleaning we will save any data modifications in new csv which we can then upload to datasette. This way our data stays immutable.
df = get_image_df(path)
get_images_from_df(path, df=df)(#309) [Path('/mnt/d/rahuketu/programming/AIKING_HOME/data/PandemicSafety/No_Mask/7a8b0909-4f5c-4d53-b1bc-f35a83a022c9.jpg'),Path('/mnt/d/rahuketu/programming/AIKING_HOME/data/PandemicSafety/No_Mask/1f54d9ac-4a0e-42fe-98cb-09938a3104b0.jpg'),Path('/mnt/d/rahuketu/programming/AIKING_HOME/data/PandemicSafety/No_Mask/d08a498f-27cf-4668-a4f1-af32dfd15416.jpg'),Path('/mnt/d/rahuketu/programming/AIKING_HOME/data/PandemicSafety/No_Mask/52601346-132e-4217-ab57-6c324c1e4eee.jpg'),Path('/mnt/d/rahuketu/programming/AIKING_HOME/data/PandemicSafety/No_Mask/78ac55fb-2db3-48e9-bdcc-4caa2a50e3f6.jpg'),Path('/mnt/d/rahuketu/programming/AIKING_HOME/data/PandemicSafety/No_Mask/5eeec12d-174e-4d1d-a261-8dcd99ea9b8b.jpg'),Path('/mnt/d/rahuketu/programming/AIKING_HOME/data/PandemicSafety/No_Mask/f048f38a-3758-428d-8d9f-8462a4e272d0.jpeg'),Path('/mnt/d/rahuketu/programming/AIKING_HOME/data/PandemicSafety/No_Mask/cfbe3224-4ec8-47f6-8ee8-d637572b2787.jpg'),Path('/mnt/d/rahuketu/programming/AIKING_HOME/data/PandemicSafety/No_Mask/b2b14d80-ddf9-4e4a-9b61-afdbabb1cf9d.jpg'),Path('/mnt/d/rahuketu/programming/AIKING_HOME/data/PandemicSafety/No_Mask/d7a7b4e3-4756-4294-88d6-6c23a7ba6741.jpg')...]dls = ImageDataLoaders.from_lists(path,
fnames=get_images_from_df(path, df=df),
labels=df['label'].values.tolist(),
valid_pct=0.5,
item_tfms=[Resize(192, method='squish')])
dls.valid.show_batch(max_n=6)
Model Training
learn = vision_learner(dls, resnet18, metrics=[error_rate, accuracy]); learn<fastai.learner.Learner at 0x7f26f76976a0>learn.fine_tune(8)| epoch | train_loss | valid_loss | error_rate | accuracy | time |
|---|---|---|---|---|---|
| 0 | 1.429095 | 3.356303 | 0.564935 | 0.435065 | 00:24 |
| epoch | train_loss | valid_loss | error_rate | accuracy | time |
|---|---|---|---|---|---|
| 0 | 0.771222 | 2.435999 | 0.532468 | 0.467532 | 00:21 |
| 1 | 0.655559 | 2.050427 | 0.512987 | 0.487013 | 00:19 |
| 2 | 0.518054 | 1.739411 | 0.409091 | 0.590909 | 00:19 |
| 3 | 0.391933 | 1.455391 | 0.344156 | 0.655844 | 00:20 |
| 4 | 0.315473 | 1.216033 | 0.233766 | 0.766234 | 00:19 |
| 5 | 0.265082 | 0.994206 | 0.214286 | 0.785714 | 00:19 |
| 6 | 0.222884 | 0.825363 | 0.214286 | 0.785714 | 00:19 |
| 7 | 0.191623 | 0.693891 | 0.168831 | 0.831169 | 00:18 |
Classification Interpretation
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()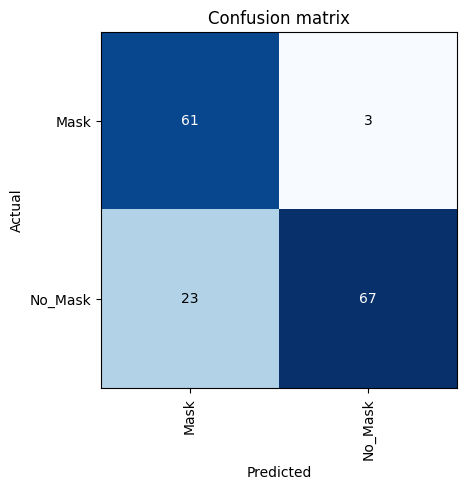
interp.plot_top_losses(k=20)
Where do we see high losses?
- When model predicts incorrect class with high confidence.
- When model predicts correct class but the confidence low.
Data Cleaning
w = PanelImageClassifierCleaner(learn, max_n=25); wdef get_new_dataset(df, mods, join_col='fn', skip_col='skipped', new_label_col='new_label', old_label_col='label'):
mods = [{join_col: k.name, skip_col: v == '<Delete>', new_label_col:[None, v] [v != '<Delete>'] } for k,v in mods.items()]
df_mods = pd.DataFrame(mods); df_mods
df_new = df[:]
merged_df = df_new.merge(df_mods, on=join_col, how='outer')
# Assign old label is new_label is NaN.
merged_df.loc[merged_df[new_label_col].isnull(), new_label_col] = merged_df[merged_df[new_label_col].isnull()][old_label_col]
# Assign skip_col = False of skip_col is NaN
merged_df.loc[merged_df[skip_col].isnull(), skip_col] = False
return merged_dfModel and Cleaned Data Saving
df_new_ds = get_new_dataset(df, mods = w.get_mods())
df_new_ds.to_csv(path/"cleaned_v1.csv", index=False)learn.export(aiking_path('model')/"pandemic_v1.pkl")