In real life many distribution are non-normal => We find skewness in distribution of data.
Distribution of how many cups of coffee some one drinks a day/ alcohol
Non drinkers - Data Clustered at zero
Low/Moderate drinkers range of usage
Addicts/ Alcoholics -Heavy drinkers
Ways data ( here financial data ) can depart from normality
Skewness - right tail left tail [ left skewed if left tail is longer than right tail]
Kurtosis - Heaviness of tails of distribution
Other ways also exists
High freq data - daily log returns are typically not normal
VaR and ES depends on left tail of returns distribution(data) so their value is impacted by nature of distribution.
What happens when the data / left tails of return is skewed but we assume it’s normal and therefor symmetric.?
If distribution is left skewed it has a much longer left tail than symmetric or longer distribution => Large negative returns are more likely in left skewed graph than the middle graph => More negative VaR and ES values.
What is the implication of heavy tailed distribution on VaR and ES?
Large outcomes positive / negative more likely in heavy tailed distribution than normal distribution => VaR and ES will not be correct when assuming normal distribution.
Test for normality
Jarque Bera Test ( JB Static very large with p-value zero -> reject normality
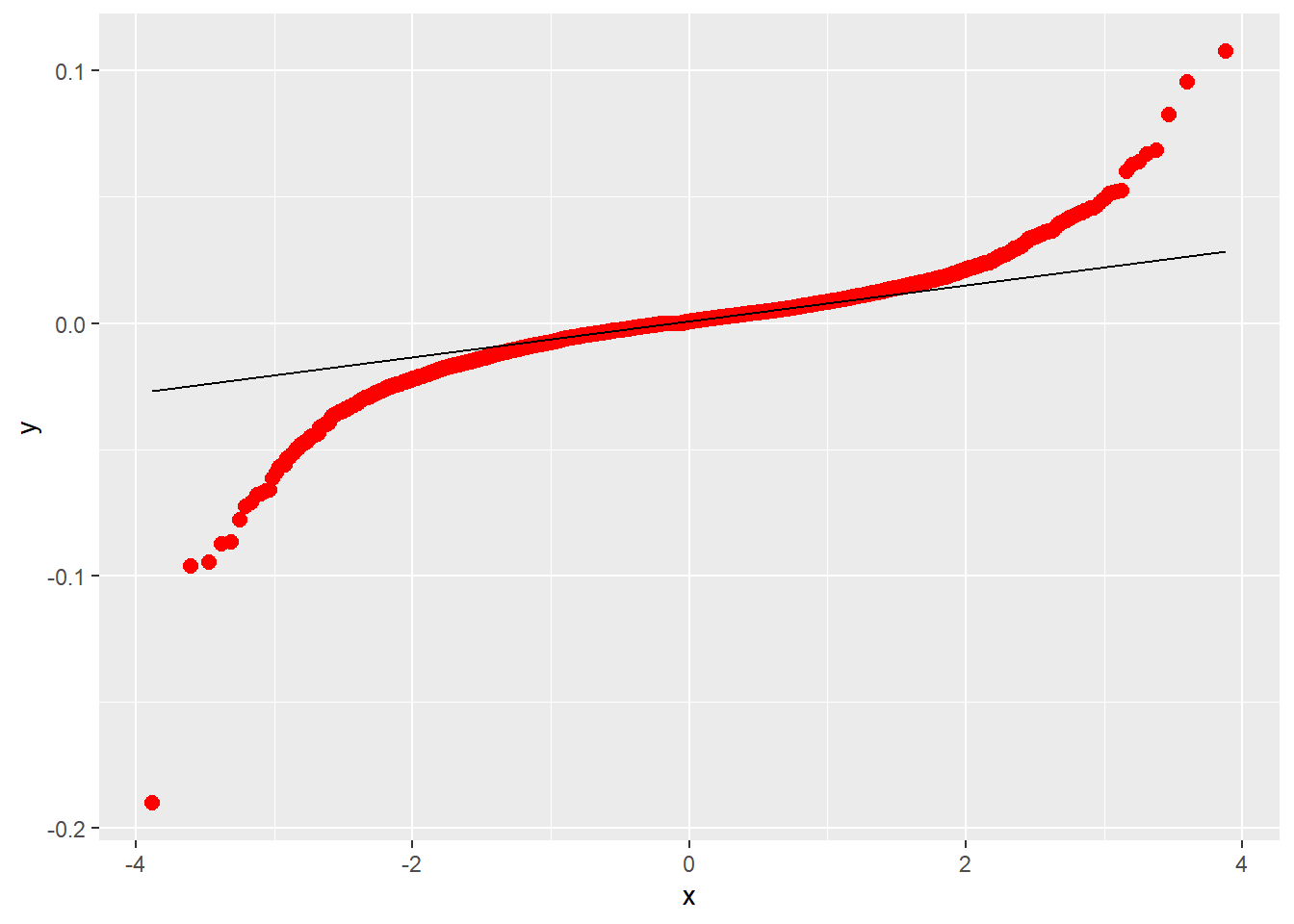
QQPlot
Kolmogorov-Smirnov Test: Histogram of actual data against histogram of assumed normal distribution
If data is not normal
Find a distribution which describes our data better than the normal distribution
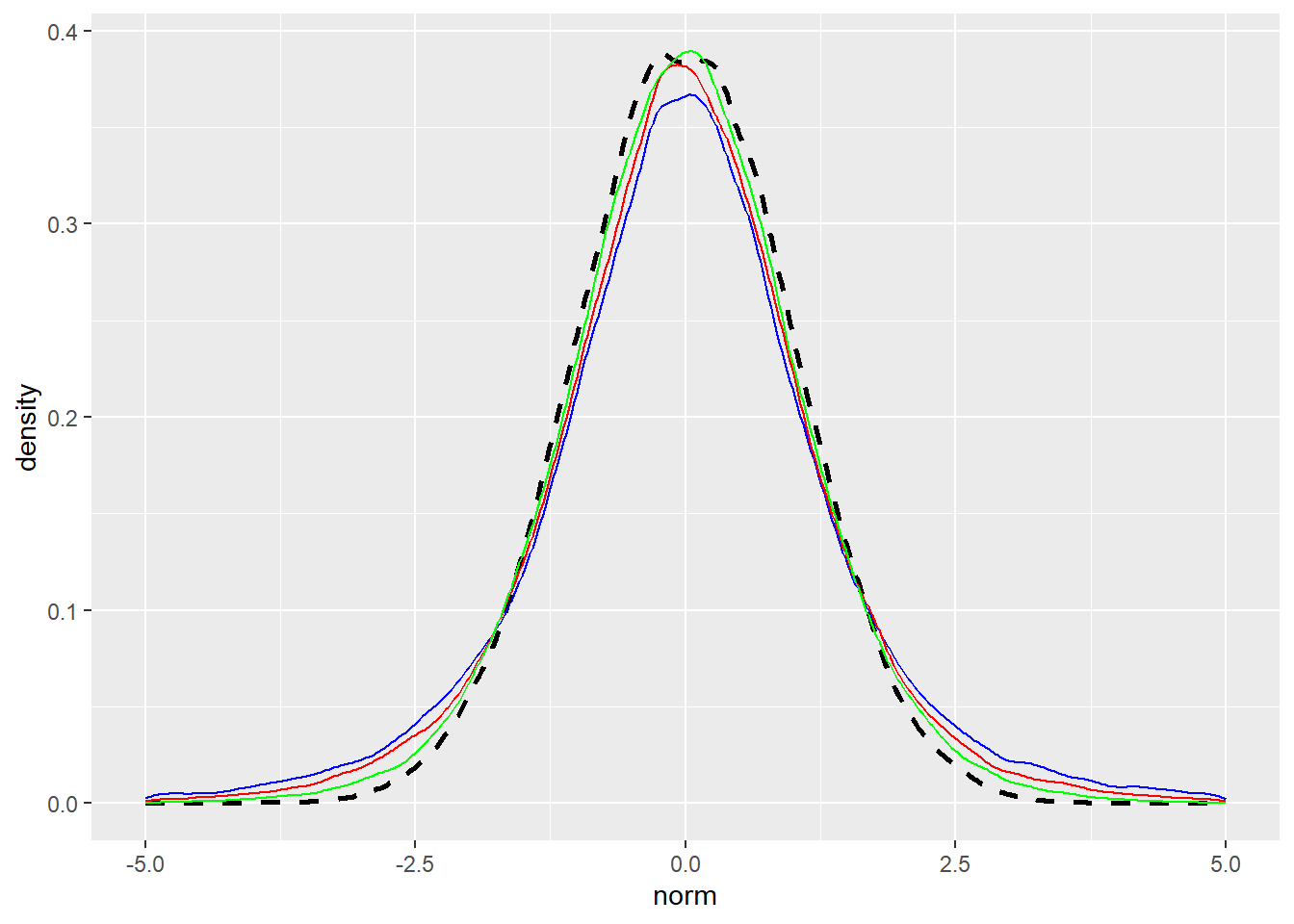
In this week we use Student-T Distribution.
Student T Distribution
Described by mean . sigma and degree of freedom(v)
Mean always 0
Variance
Skewness 0 for v> 3 otherwise undefined
Kurtosis 3+ 6/(v-4) for v>4, infinity for 2 < v <= 4, otherwise undefined
At v -> infinity , it is normal distribution.
Implies, T-distribution family include normal distribution as a special case.
Degree of freedom controls the shape of the distribution
Student T- has heavier tail than normal (Kurtosis=3)
Differ from normal distribution in term of
Same mean and Skewness
Differ Std. Dev - not that important
Kurtosis is higher
Degree of freedom get larger =>Kurtosis get’s smaller.
How do you match Student-T distribution to data?
Problem - Find distribution which match standard deviation and Kurtosis student T distribution to the data.
Since we only have single parameter here which is v. We do a trick to solve
We need to create 2 equation with 2 unknown => Use Rescaled T-distribution.
Divide distribution by root of v/v-2.
First find v by matching kurtosis value of data with Rescaled T-Distribution.
Pick a scaling parameter to match standard deviation of data.
s <- wilsh |>logret_1() |>logret_ndays(days=10) |>get_sim_series()VaR <- s |>get_sim_VaR(alpha=0.05); VaR
[1] -0.04700005
ES <- s |>get_sim_ES(VaR=VaR); ES
[1] -0.07780043
This is probably a nicer way to simulate block based simulation first by calculating logret_10 and then simulating the regular series. Only challenge is because of randomness, we can’t match results with exactly with random number seed process. So let’s implement a block based approach that exactly matches our answer from presentation.