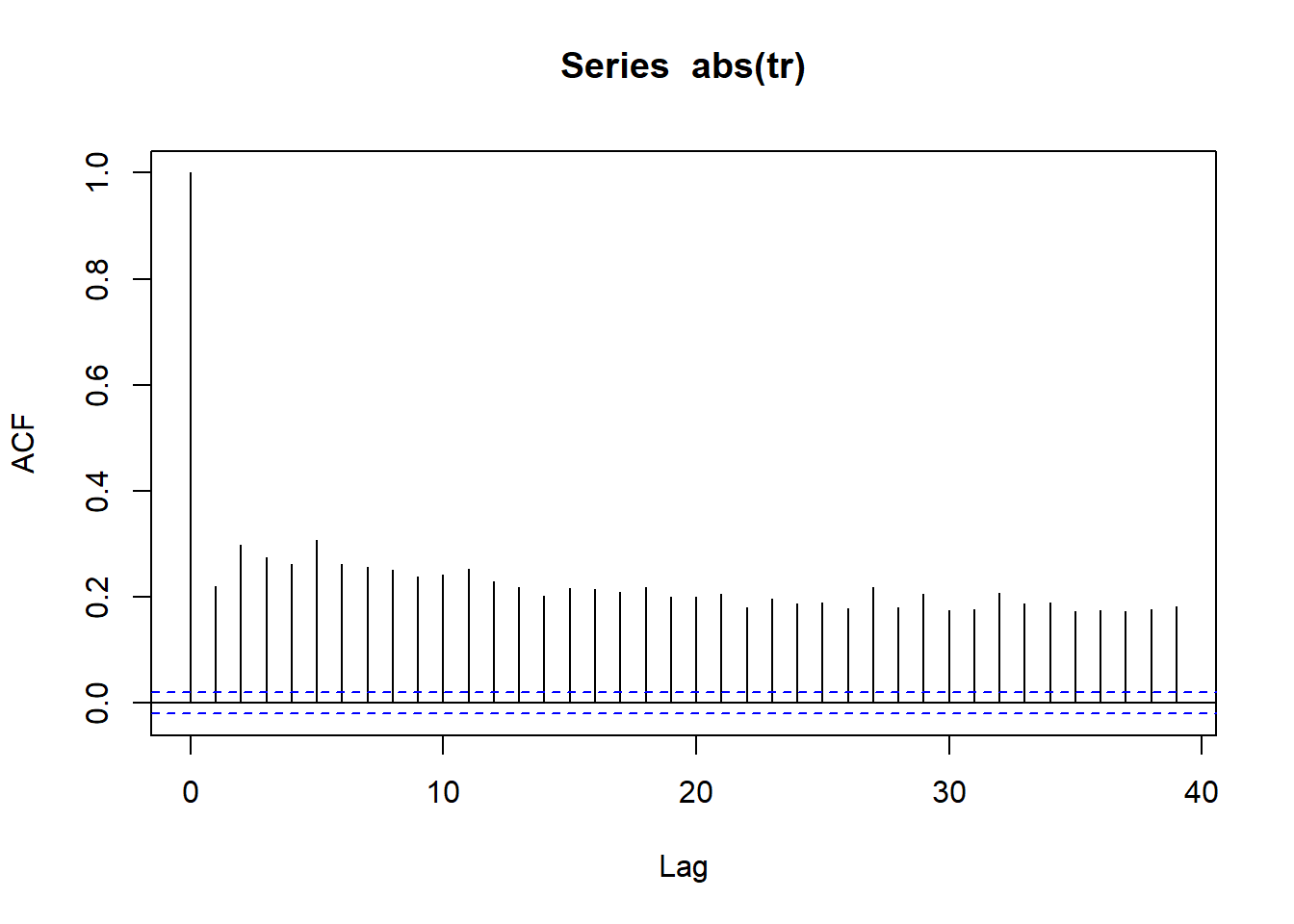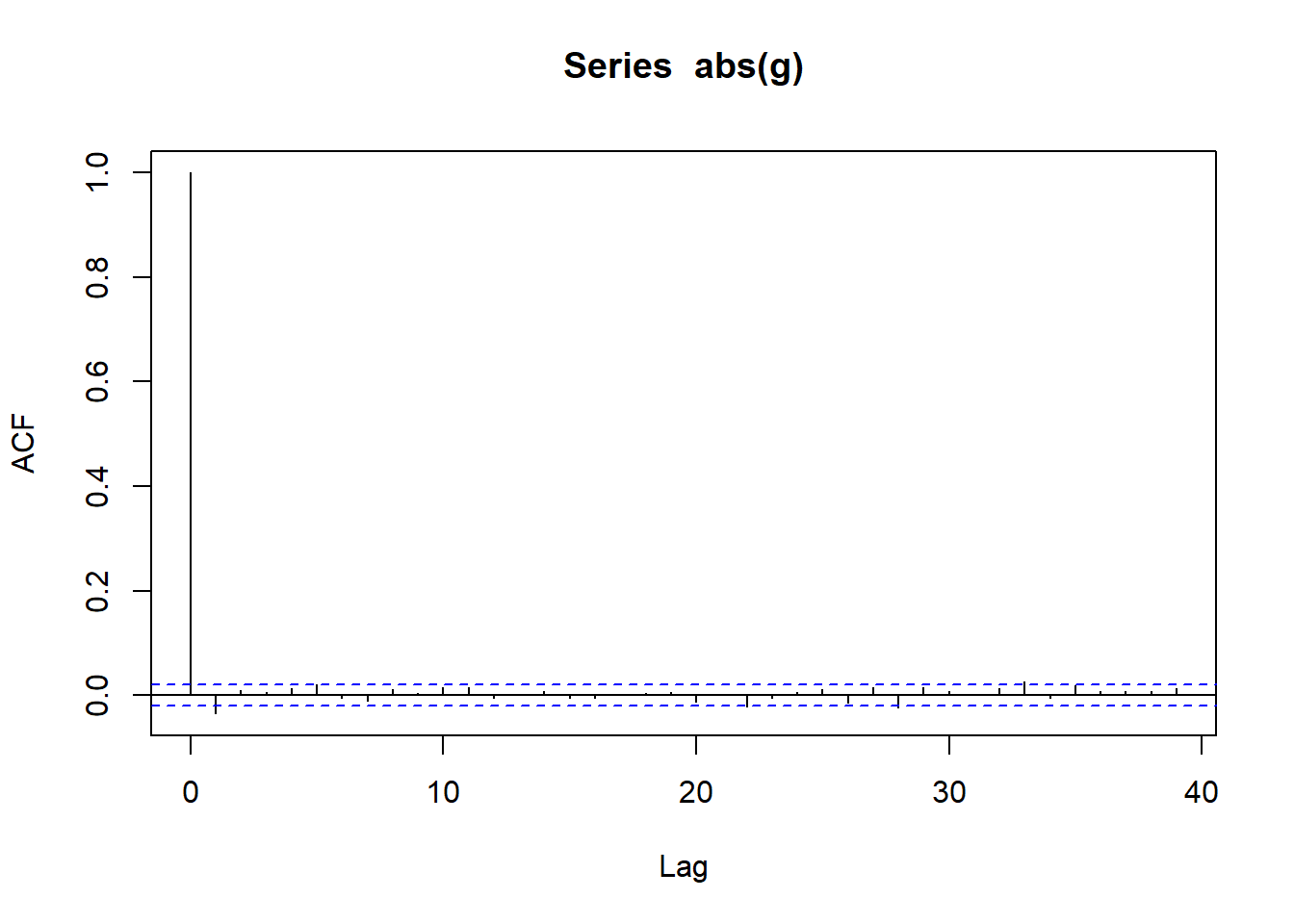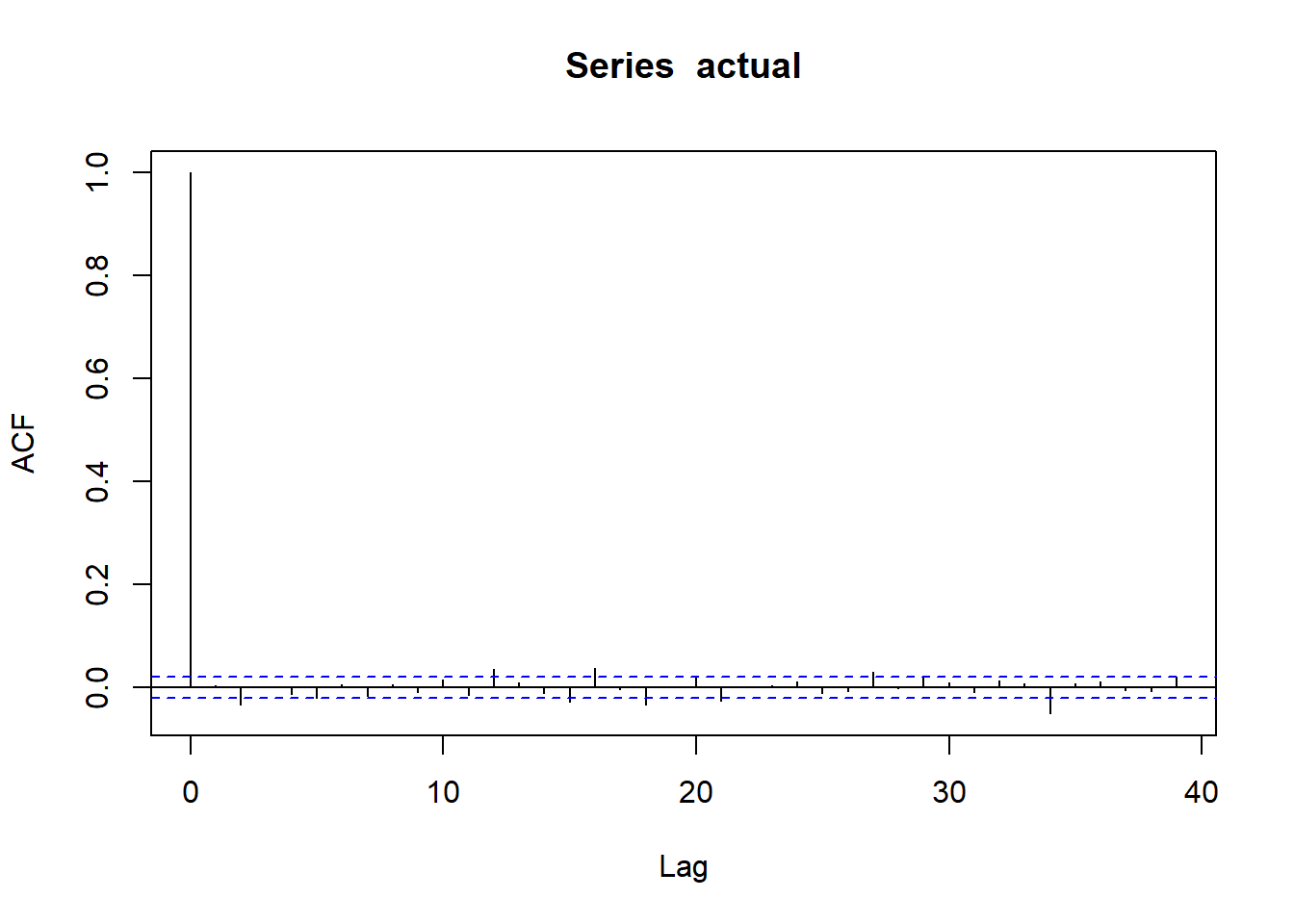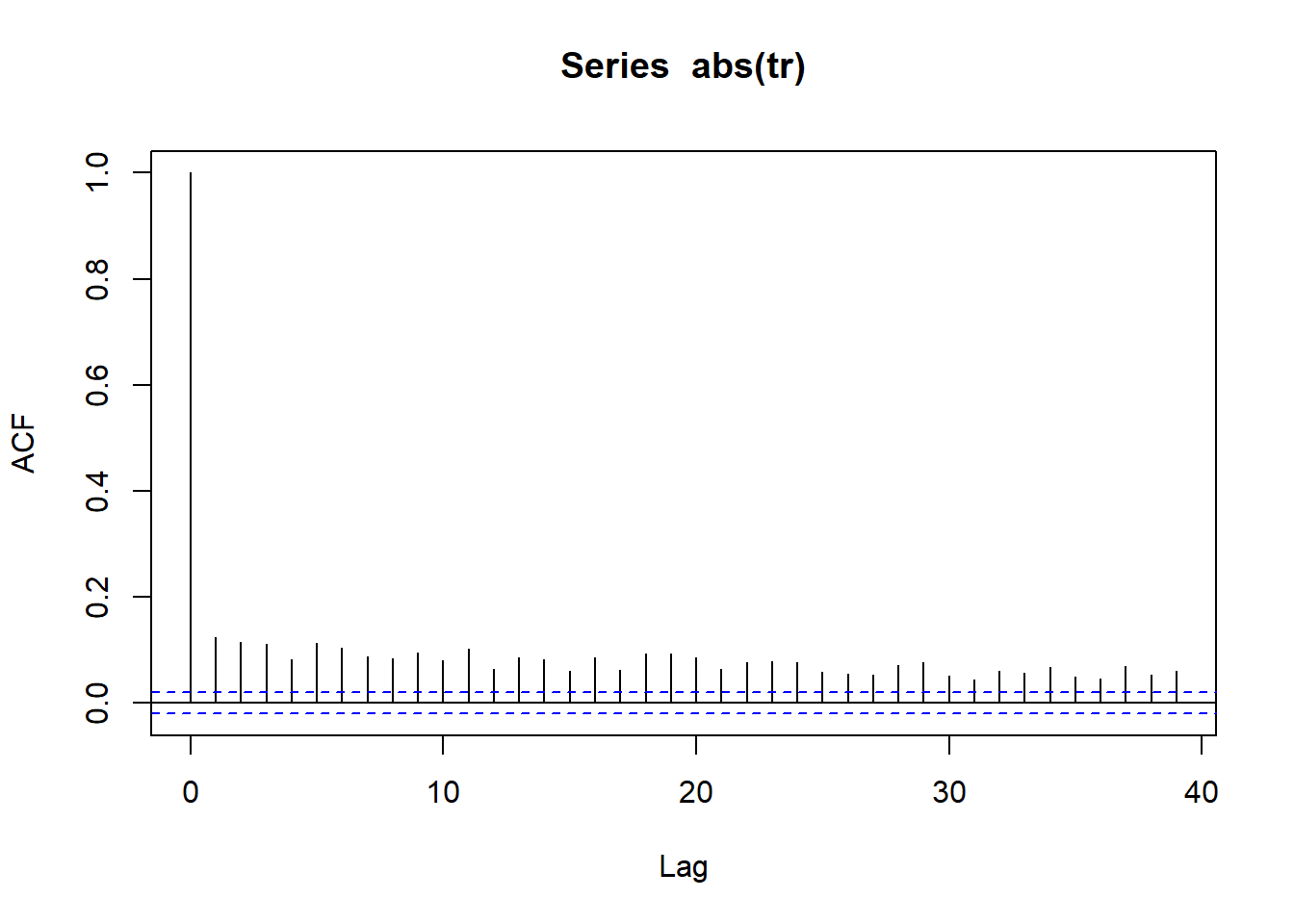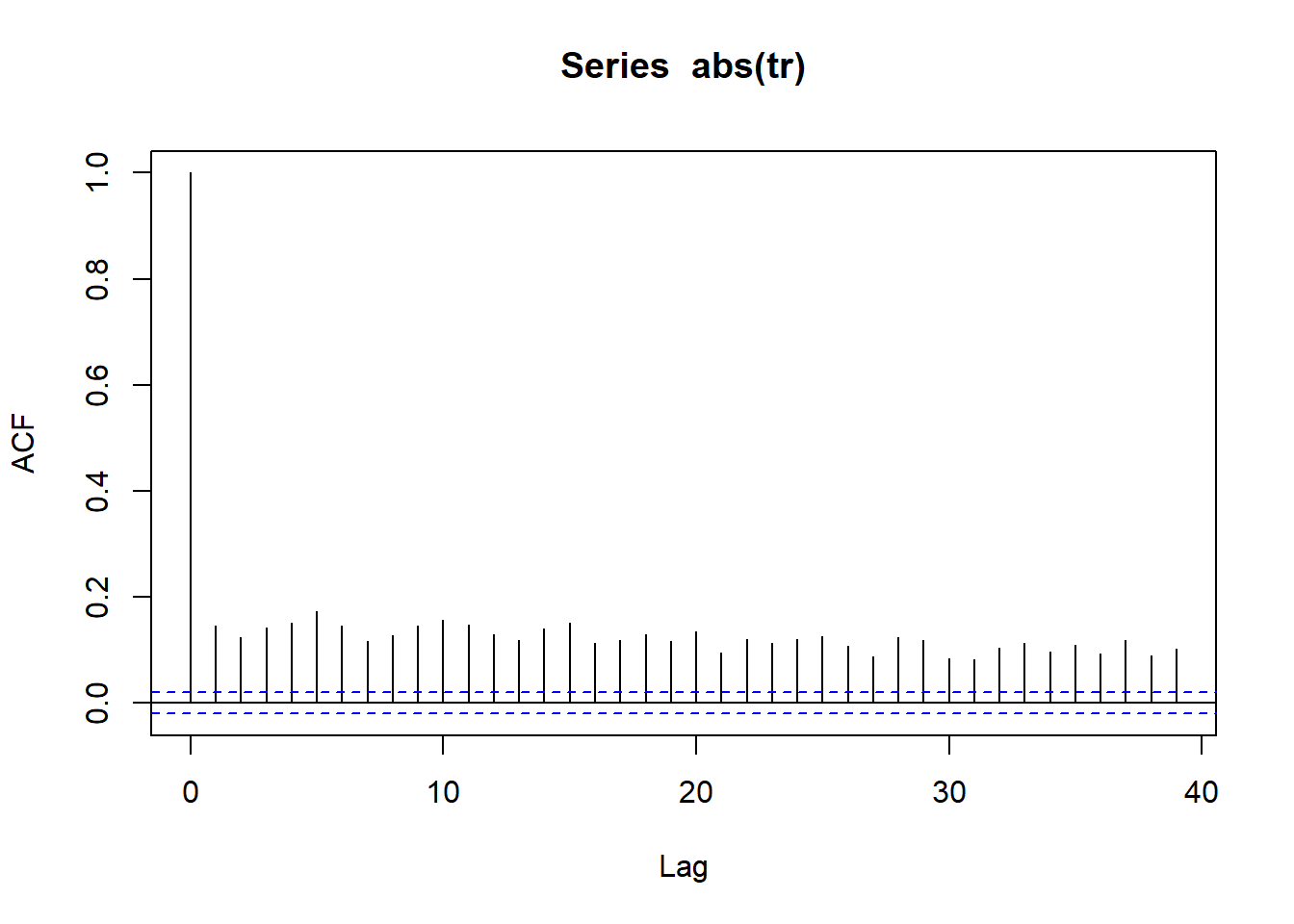To create a statistical model for future returns , in particular the left tail.
Model if often based on historical returns ( the only thing that we can observe)
Future Distribution of Returns(TR) = Function (Historical Returns , Some assumptions)
Modelling assumptions so far
Future Distribution ( WILSHIRE 5000/ index fund) == Historical Distribution ( True for some time but not always)
Currently our distribution of choice is re-scaled T-distribution as it models the data better than normal distribution .
We have also simulated observed distribution from the data
Parameters of historical distribution ( mean, sigma and/ or df) are calculated without paying attention to the ordering of the data
Implies, even if we randomly permeates logret series distribution parameter will still be same.
What if we have some information in the past which can inform us about the future distribution for logret? In other words, what is the impact of serial correlation if any.
Serial correlation
Positive serial correlation - an above average return ( > mean) tend to be followed by another above - average return
Negative serial correlation - above average return is followed by below average return
No correlation / random wal k - an above average return does not increase the likelihood of being followed by an above avg or below avg return.
There was a long history of research in financial markets that look at serial correlation. Now to understand what serial correlation means,
Correlation - let’s start with the correlation between two variables, let’s say, X and Y. The correlation coefficient between X and Y measures how they co-move together. We say that X and Y are positively correlated when they tend to move up and down together. To be more precise, if X is above its mean, then Y is likely to be also above its mean.
Serial correlation - How a variable X and its own past are correlated?
Significance of serial correlation in Finance is associated with the concept of Market Efficiency.
The theory of market efficiency says that the observed price of an asset such as a stock, fully reflects all information about that asset
When new information comes in, it will change the price of the asset. Good news presumably will lead to an increase in its price. Conversely, bad news will lead to a decrease in its price.
Now, because all existing information has been incorporated in the price of an asset, any new information must be a surprise.
If the surprise is good news, the price of the asset will go up, and if the surprise is bad news, the price of the asset will go down. But there is no way to tell ahead of time whether the news is good or bad. So there is no way to tell if the price will go up or down.
This is so called random walk model of prices.
This random walk model just says there is no way to predict if the future price of an asset will go up or go down relative to its current price.
An implication of the random walk model is that returns have no serial correlation. So testing for serial correlation in stock return has been viewed as testing for market efficiency
Motivation & Definition for Volatility Clustering - In financial time series data, it is often observed
Large returns +ve/ -ve negative tend to be followed by more large returns
High Volatility days are followed by more High Volatility days
Low Volatility days are followed by more Low Volatility days
This phenomenon is called Volatility clustering
It is calculated mathematically by measuring autocorrelation of absolute values of log returns
A time series exhibiting Volatility clustering implies ordering of the data is important
Strong volatility clustering implies we can predict volatility of stock prices for future values based on the past values.
This is exploited in GARCH model ( Generalized Auto-regressive Conditional Heteroskedasticity)
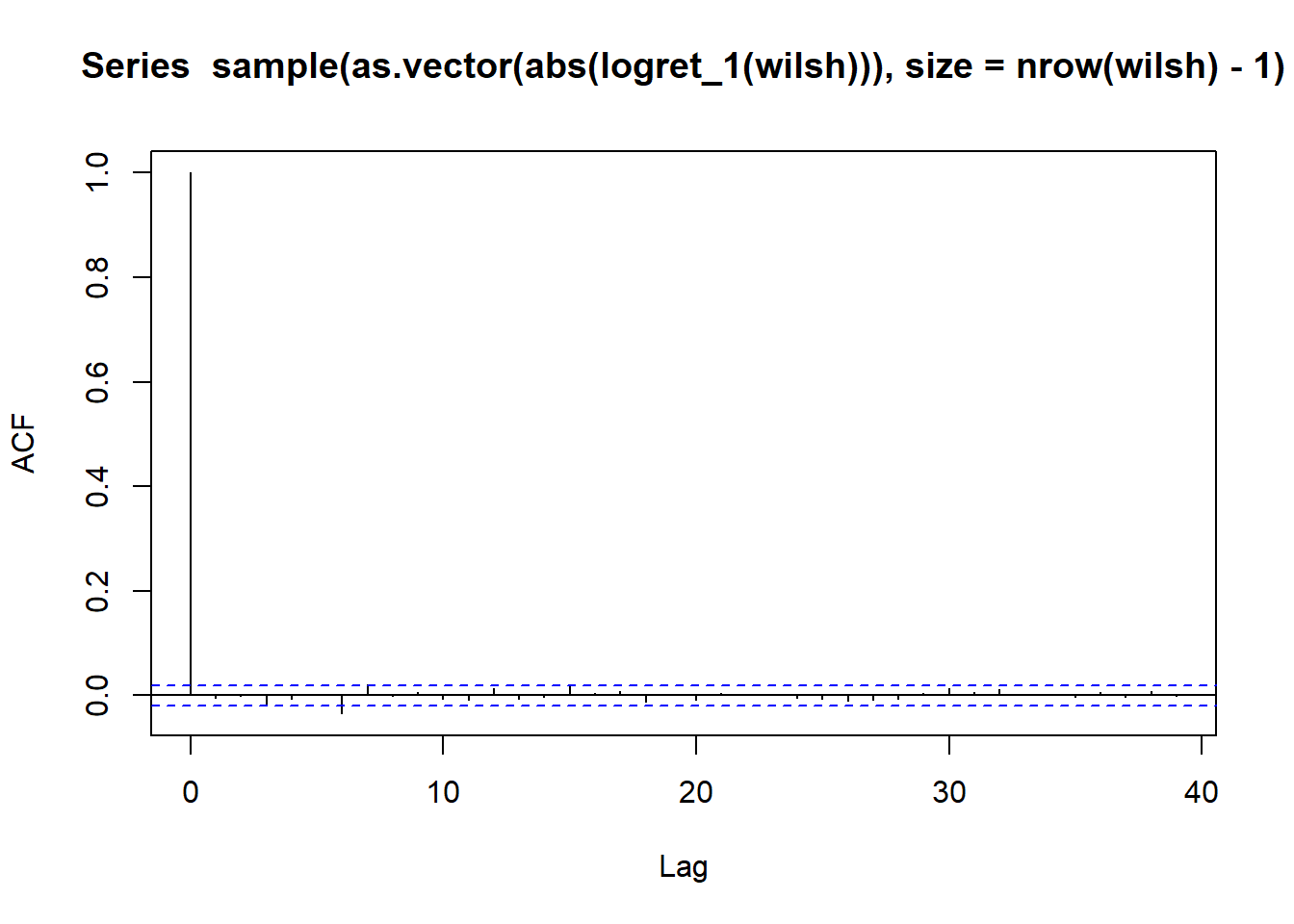
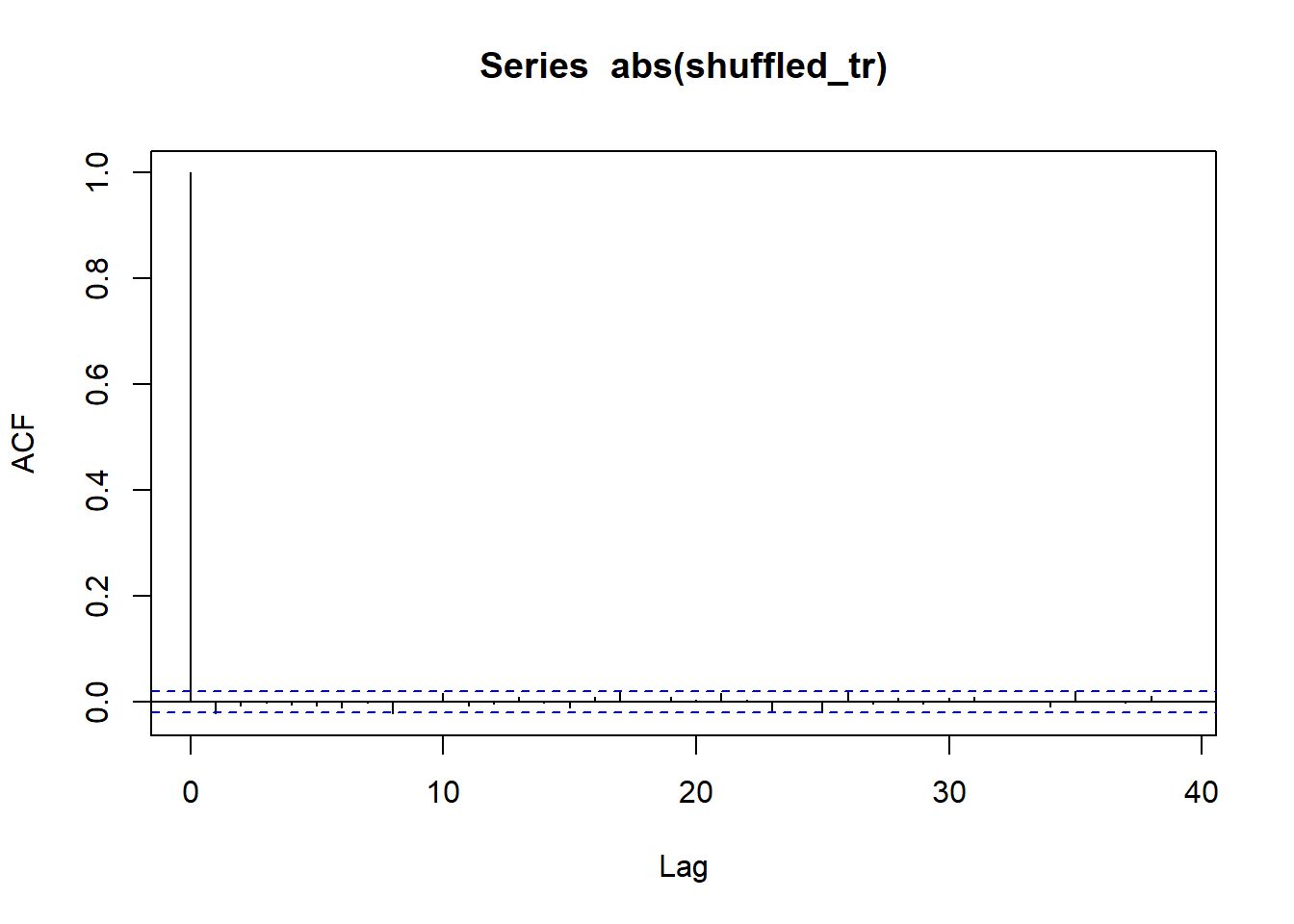
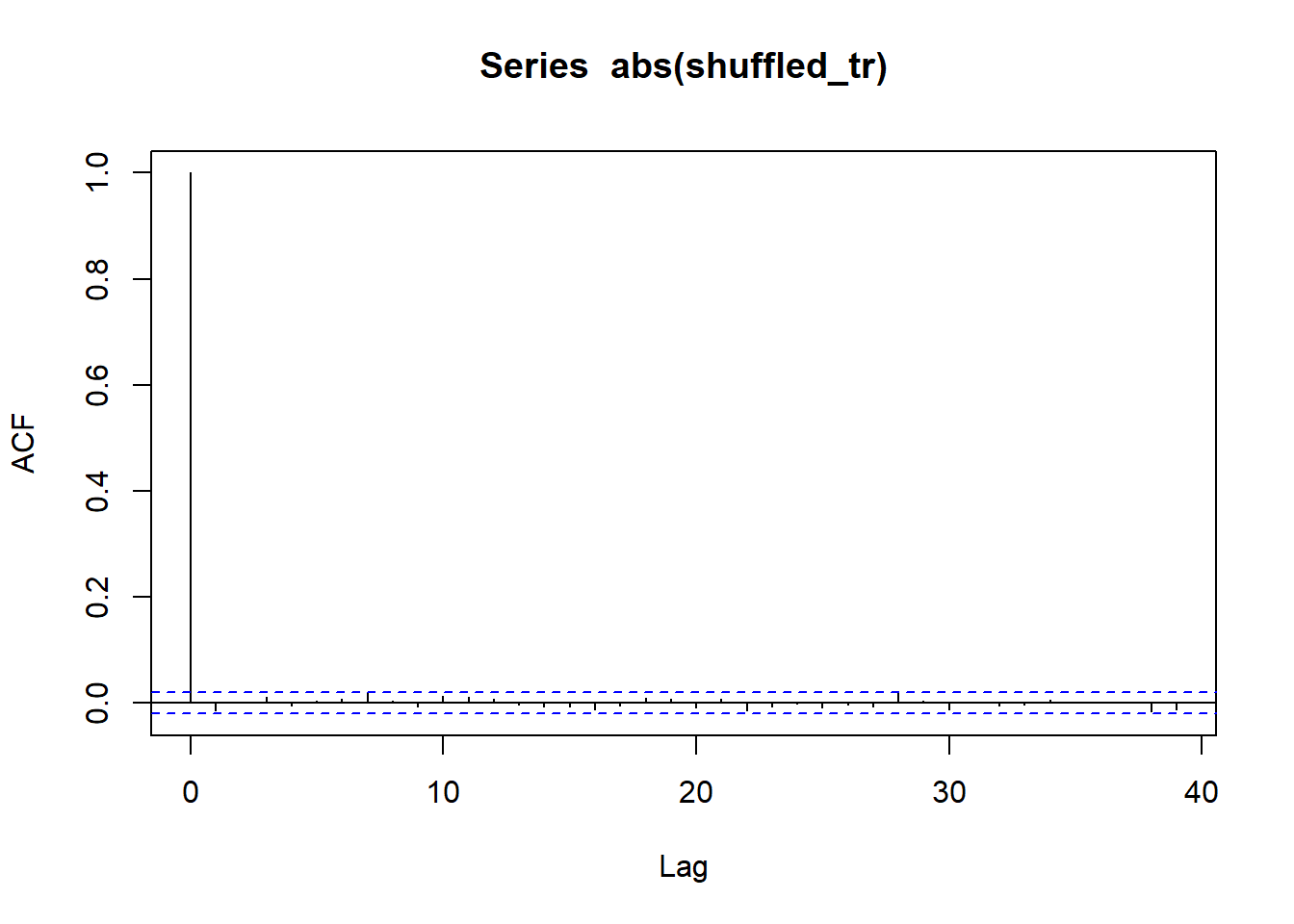
We can test volatility clustering/ effect of ordering by
Plotting acf on absolute values of logreturns - ( Should show strong evidence of serial correlation )
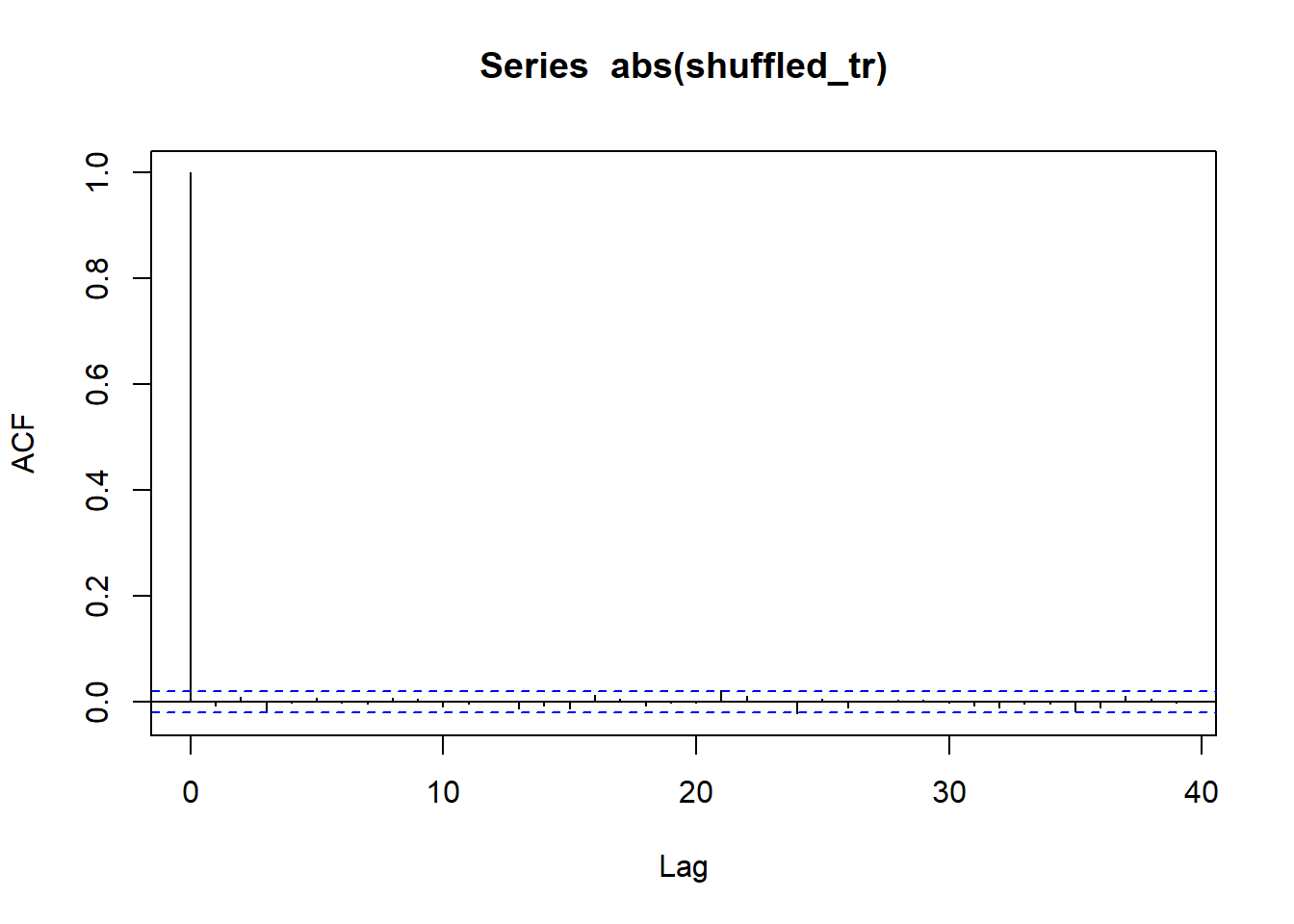
Shuffling/ Permeating returns and apply same logic again ( Should show no evidence of serial correlation on shuffled series)
GARCH model
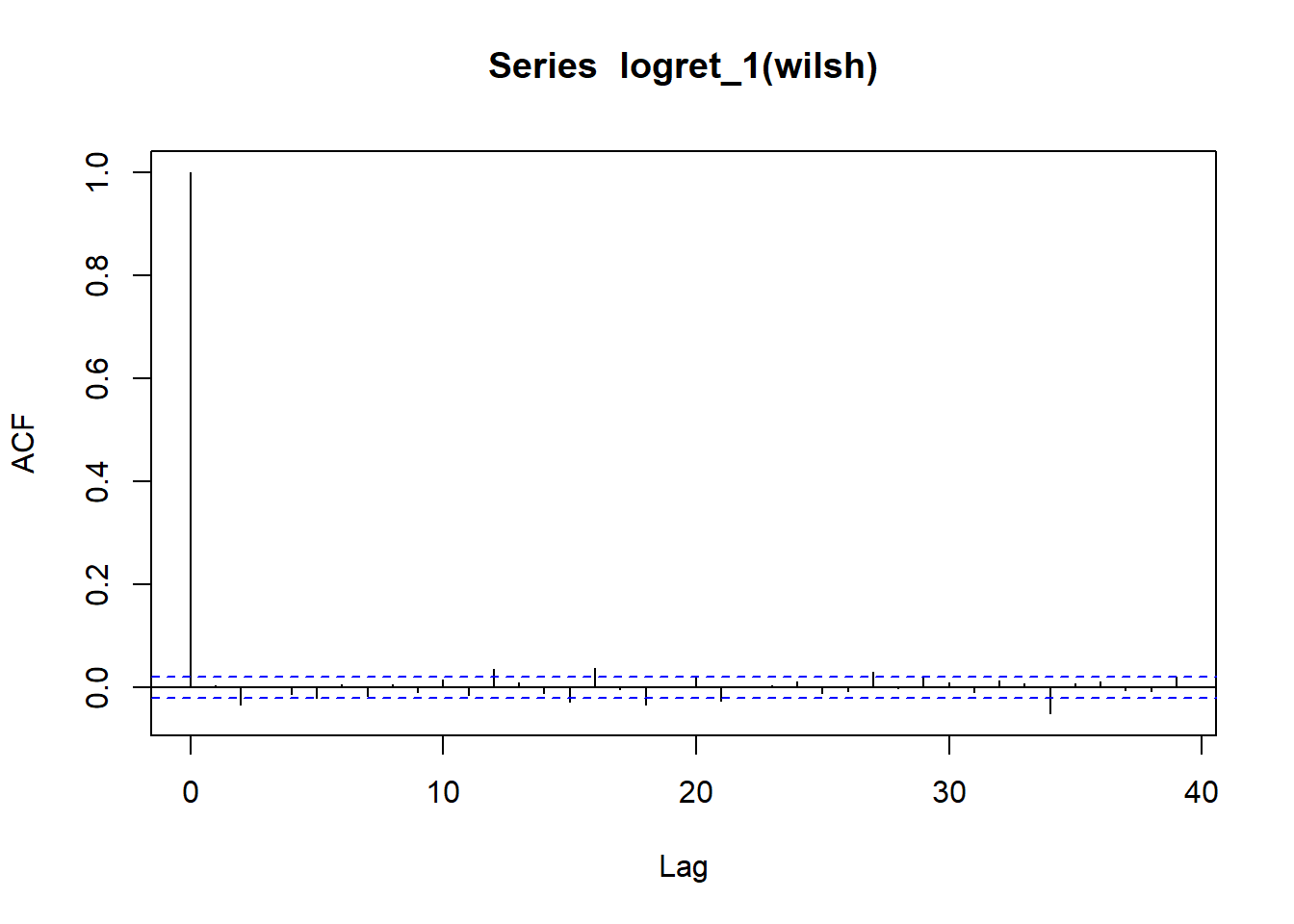
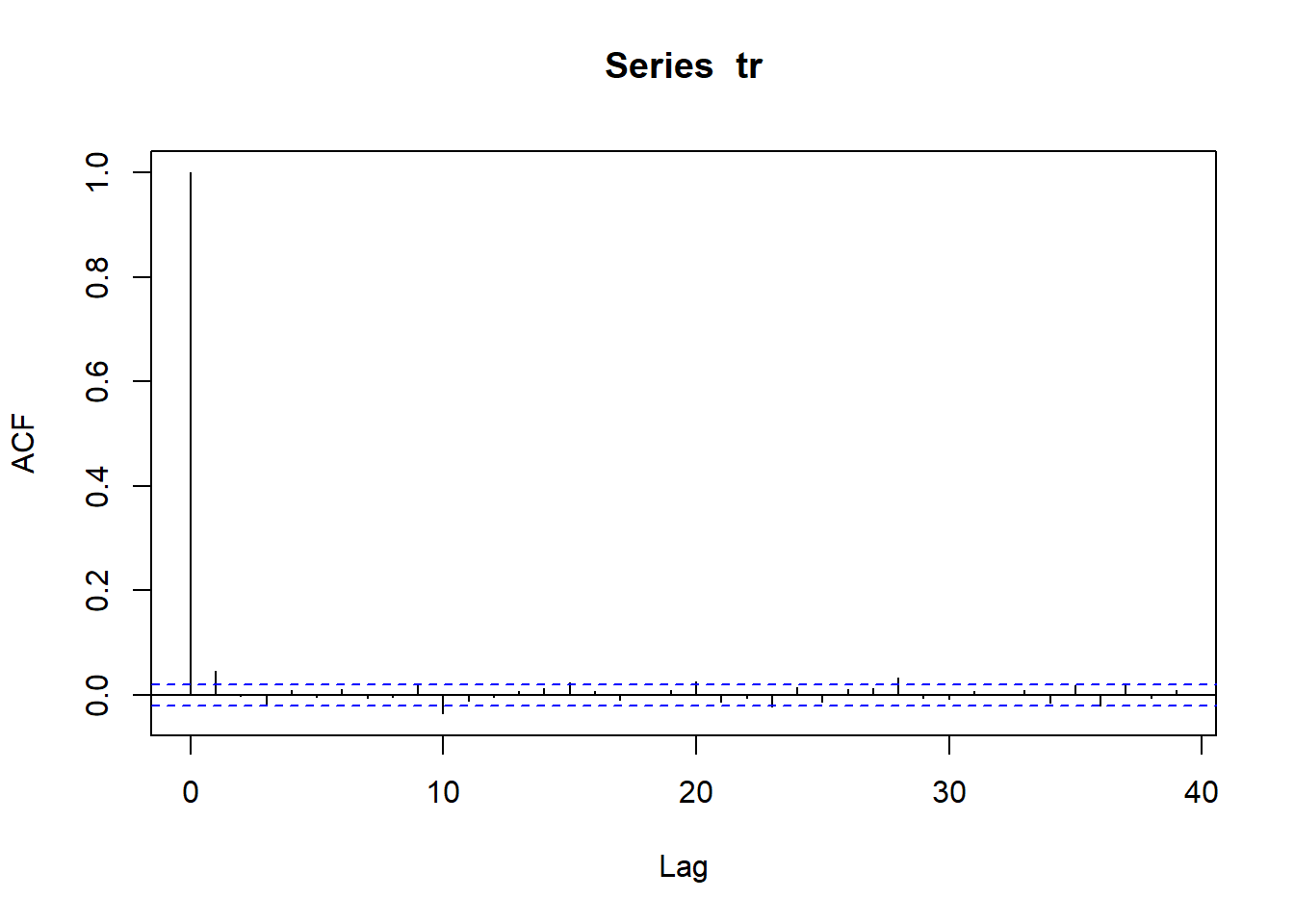
WILSHIRE 5000 ACF plot indicates no/ weak evidence of serial correlation => Difficult to predict mean of future values based on historical values
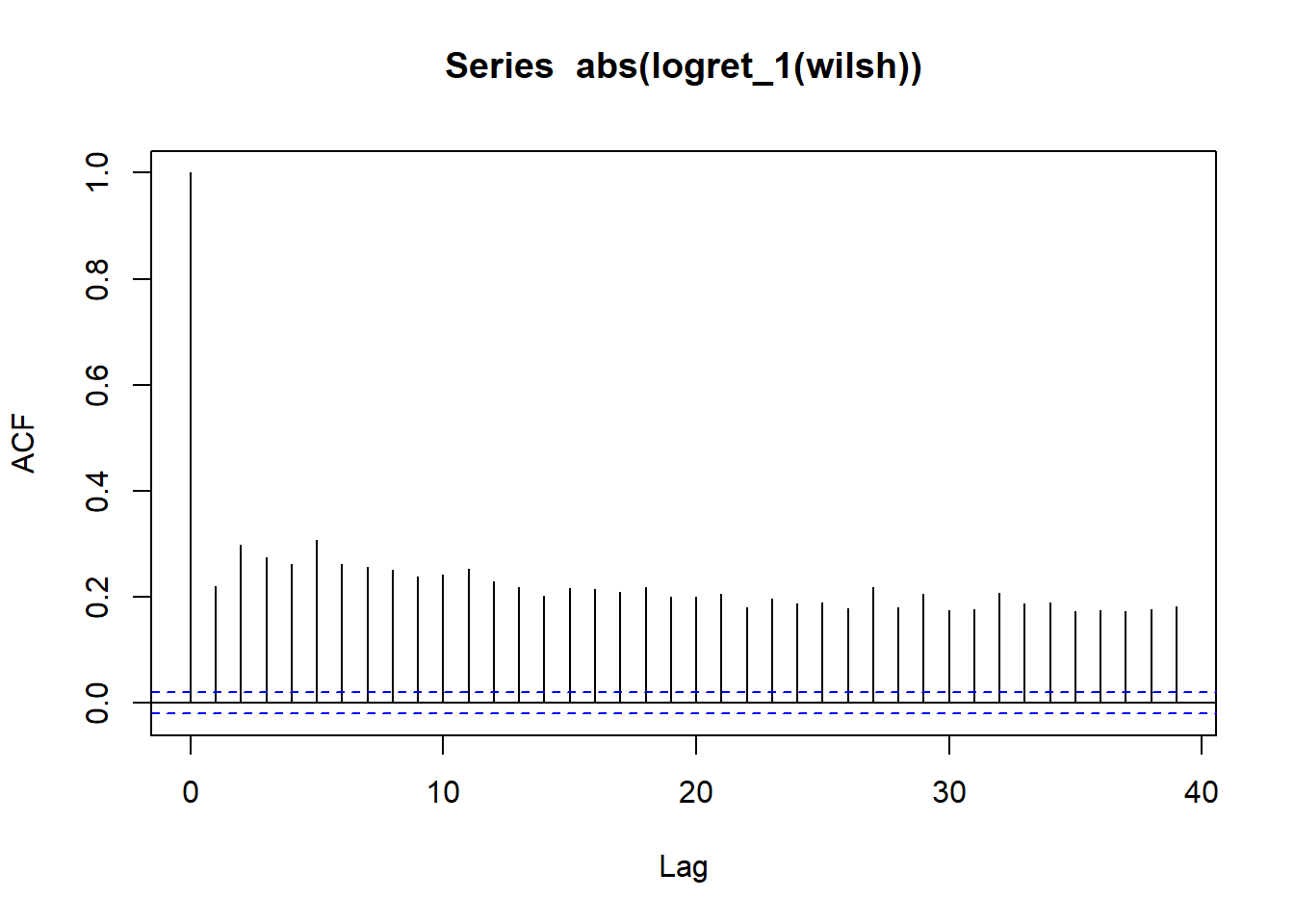
WILSHIRE 5000 ABS(ACF) plot indicates strong volatility clustering =>Volatility / Standard Deviation is changing over time in a predictable manner.
What we want is a statistical model which allows us to predict future volatility- GARCH
GARCH model has many extensions. We are going to focus on GARCH(1,1). It is one of the simplest GARCH model .But it does a very good job on WILSHIRE 5000 data in modelling volatility clustering.
GARCH(1,1)-normal model is equivalent to normal model when we assume constant variance.
Equations
Notations:
: Expected Returns
: Unexpected Returns
: Total returns of series with time varying volatility
: predictable variance of changing over time
: Normal Distribution
If is constant above equation reduces to normal model for logret.
For Volatility clustering to happen:
GARCH(1,1)-t model is equivalent to normal model when we assume constant variance.
Equations
Here we replace chosen distribution (norm) with re-scaled -t model
1-day ahead garch model can be simulated using ugarchboot function.
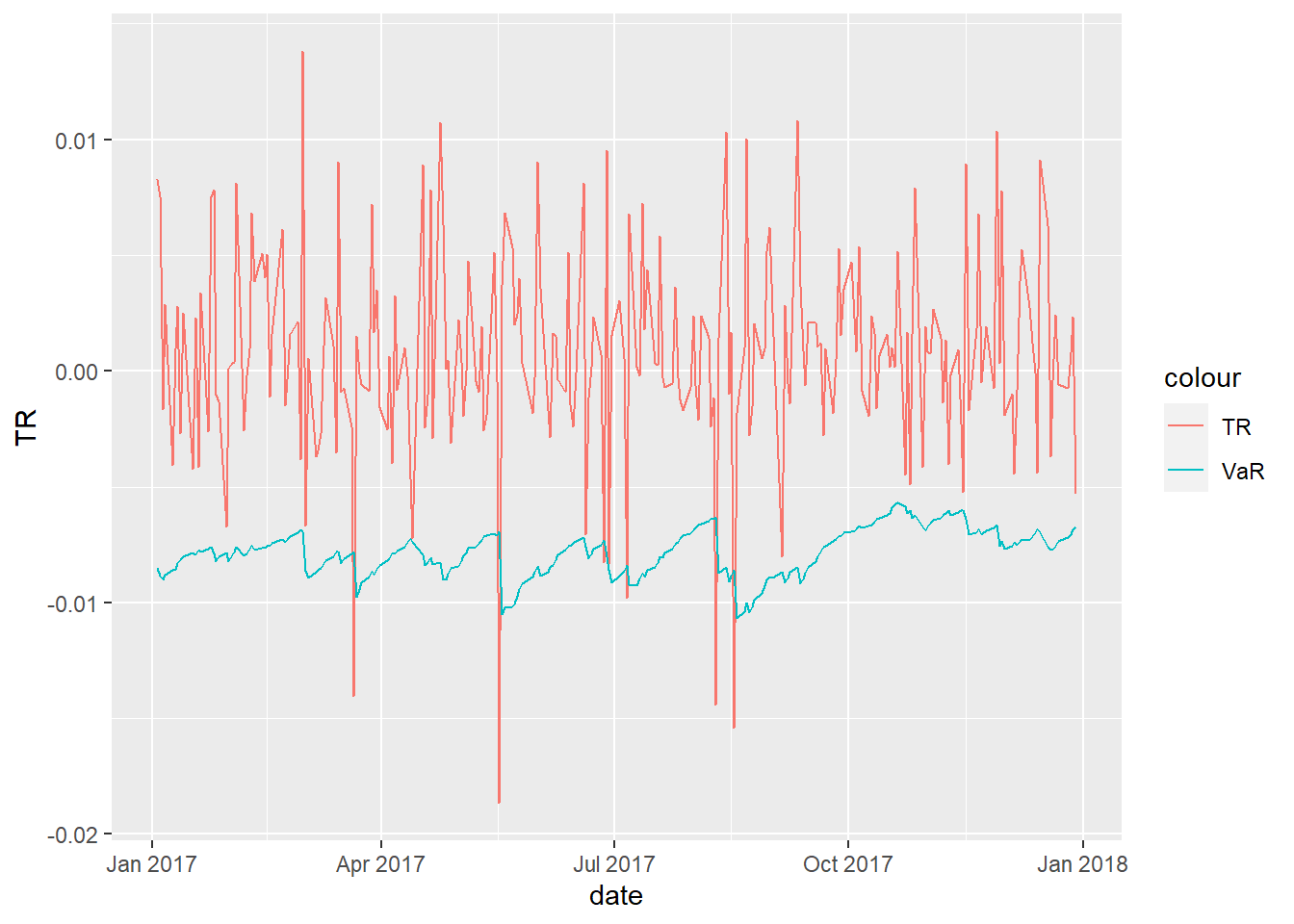
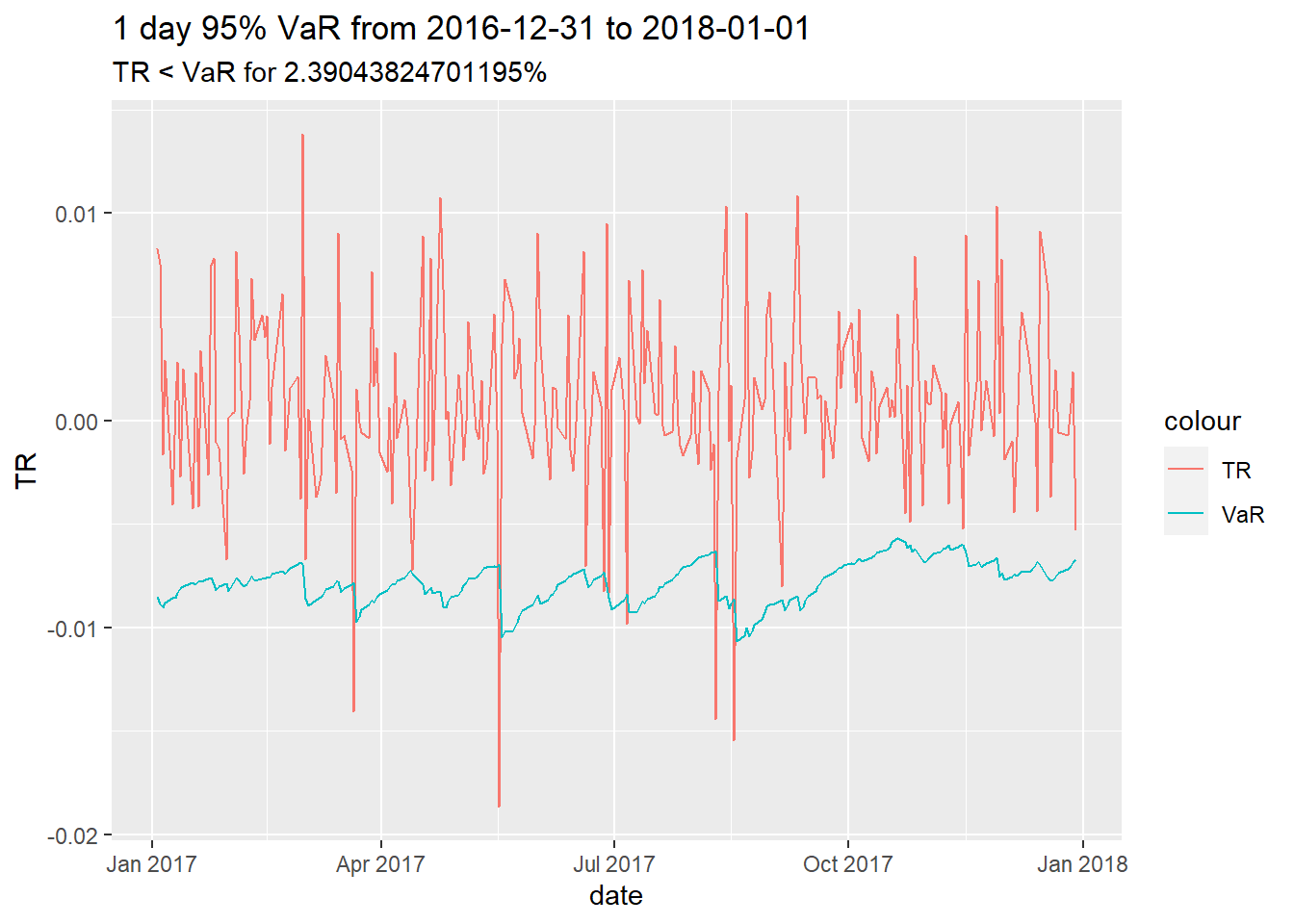
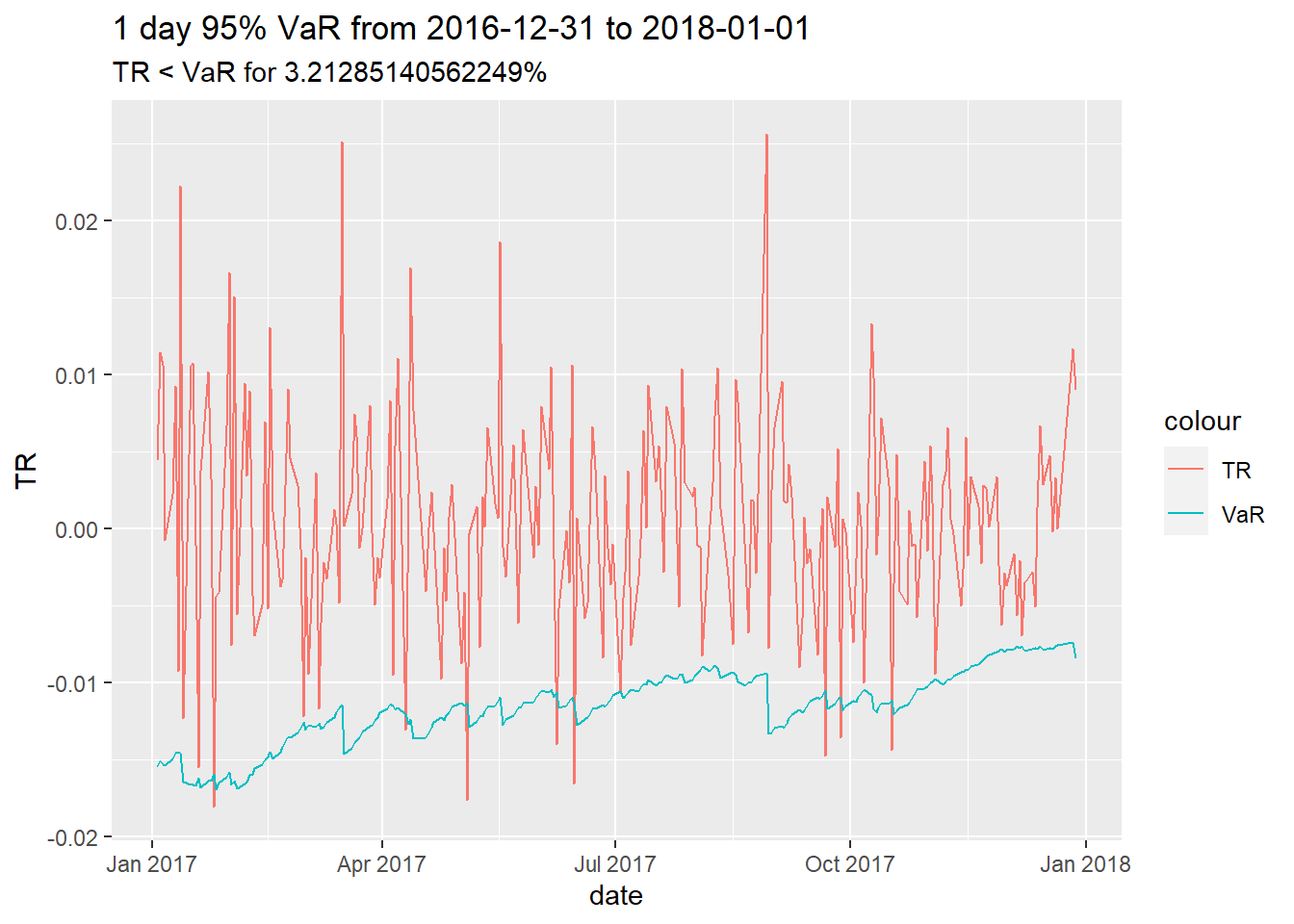
VaR and ES from garch take time ordering into account
When Fitted values are low => VaR and ES are also low.( Only apply for 1-day)
Why is GARCH model better?
When volatility is high => Risk is also high => Portfolio manager can take some action to mitigate risk
When volatility is low => Risk is low => No action as risk reduction may be costlier to portfolio.
VaR graph can be produced by using ugarchroll function.
Summary
Basics of Financial risk management
Analyze logret of portfolio
Distribution: typically non-normal
We also have volatility clustering : a behavior typical of asset returns
GARCH(1,1)-t can explain both
VaR and ES change over time
Ideas can be applied to different types of portfolios
Margin borrowing: $10 K stocks with
$5K your money
$5k from a brokerage firm
This is a margin position
You are hoping to make money from stock price going up
Risk -> Price can go down. How much money can you afford to loose -> ES over a time period( like 10 days) with a certain confidence level( like 95%)
Stock/Bond Portfolio:
Retirement Account
50% US Equities
50% long term corporate bond
Plan to retire in 1 year
No plan to add more money or take money out next year
How much can you loose in 1 year?
Can you afford to loose this amount of money for retirement in 1 year?
Imports
library(quantmod)
Loading required package: xts
Loading required package: zoo
Attaching package: 'zoo'
The following objects are masked from 'package:base':
as.Date, as.Date.numeric
Loading required package: TTR
Registered S3 method overwritten by 'quantmod':
method from
as.zoo.data.frame zoo
The following objects are masked from 'package:base':
cbind, rbind
library(rugarch)
Loading required package: parallel
Attaching package: 'rugarch'
The following object is masked from 'package:purrr':
reduce
The following object is masked from 'package:stats':
sigma
Set Seed.
RNGkind(sample.kind="Rounding") set.seed(123789)
Functions
Show the code
filterSeries <-function(s, date_filter="1979-12-31/2017-12-31", new_name='TR'){ s <-na.omit(s); s s <- s[date_filter]; snames(s) <- new_name; sreturn(s)}getSeries <-function(name, date_filter="1979-12-31/2017-12-31", src='FRED', new_name='TR', auto.assign=FALSE){ s <-getSymbols(name, src=src, auto.assign = auto.assign); s s <-filterSeries(s)return(s)}get_df <-function(tbl){ df <-data.frame(date=index(tbl), TR=as.numeric(tbl$TR))return(df)}logret_1 <-function(tbl){return(diff(log(tbl))[-1])}aggr_fn <-function(tbl, fn){ result <-fn(tbl, sum)return(result)}logret_w <-partial(aggr_fn, fn = apply.weekly)logret_m <-partial(aggr_fn, fn = apply.monthly)logret_q <-partial(aggr_fn, fn = apply.quarterly)logret_a <-partial(aggr_fn, fn = apply.yearly)logret_ndays <-function(tbl, days=10){ len_tbl <- (nrow(tbl)-days+1) new_TR <-sapply(seq(1:len_tbl), function(i){sum(tbl[i:(i+days-1)]) }) tbl[1:len_tbl]$TR <- new_TRreturn(tbl[1:len_tbl])}ret <-function(logret){return(exp(logret)-1)}get_norm_series <-function(mu, sig, n=100000, set_seed=TRUE){if (set_seed){RNGkind(sample.kind="Rounding")set.seed(123789) }return(rnorm(n,mu, sig)) }get_sim_series <-function(s, n=100000, set_seed=TRUE){if (set_seed){RNGkind(sample.kind="Rounding")set.seed(123789) }return(sample(as.vector(s), n, replace=TRUE))}get_t_series <-function(mu, sig, df, n=100000, set_seed=TRUE){if (set_seed){RNGkind(sample.kind="Rounding")set.seed(123789) }return(rt.scaled(n,mean=mu,sd=sig,df=df)) }get_norm_series_from_s <-function(s, n=100000, set_seed=TRUE){ mu =mean(s) sig =sd(s)return(get_norm_series(mu, sig, n=n, set_seed = set_seed))}get_fit_params <-function(s){ fitpars <- s |>as.vector() |>fitdistr(densfun='t') return(fitpars)}get_t_series_from_s <-function(s, n=100000, fitpars=NULL, set_seed=TRUE){if(is.null(fitpars)){ fitpars <- s |>get_fit_params() } t.fit <- fitparsreturn(get_t_series(mu=t.fit$estimate[1], sig=t.fit$estimate[2], df=t.fit$estimate[3], n=n, set_seed=set_seed))}get_sim_VaR <-function(s, alpha=0.05){return(quantile(s, alpha) |>unname())}get_sim_ES <-function(s, VaR){# VaR <- get_sim_VaR(s, alpha=alpha)return(mean(s[s<VaR]))}get_VaR <-function(tbl,alpha=0.05){ mu =mean(tbl) sig =sd(tbl) VaR =qnorm(alpha, mean=mu, sd=sig) #quantile of normal distribution(only not for any other distribution)return(VaR)}get_ES <-function(tbl, alpha=0.05){ mu =mean(tbl) sig =sd(tbl) ES = mu - sig*dnorm(qnorm(alpha, mean=0, sd=1), 0, 1)/alpha #quantile of normal distribution(only not for any other distribution)return(ES)}expected_loss <-function(portfolio, risk_num){ #95% confidence that we won't loose more than this amountreturn(portfolio*(exp(risk_num)-1))}err <-function(a, b){return((a-b)/a*100)}get_dist_plot <-function(tbl){ mu =mean(tbl) sig =sd(tbl) p <-get_df(tbl) |>ggplot(mapping =aes(x=TR)) +geom_histogram(aes(y=after_stat(density)), colour="black", fill="white", bins=100)+geom_density(alpha=.2, fill="violet") +geom_vline(aes(xintercept=mu),color="brown", linetype="dashed", linewidth=1) +geom_vline(aes(xintercept=mu+2*sig),color="brown", linetype="dashed", linewidth=0.1) +geom_vline(aes(xintercept=mu-2*sig),color="brown", linetype="dashed", linewidth=0.1) +labs(title=glue("Distribution of TR: mu={round(mu, 8)}, sigma={round(sig, 8)}"), y='count')return(p)}get_VaR_plot <-function(tbl, alpha=0.05){ mu =mean(tbl) sig =sd(tbl) VaR =qnorm(alpha, mean=mu, sd=sig) p <-get_df(tbl) |>ggplot(mapping =aes(x=TR)) +geom_histogram(aes(y=after_stat(density)), colour="black", fill="white", bins=100)+geom_density(alpha=.2, fill="violet") +geom_vline(aes(xintercept=mu),color="brown", linetype="dashed", linewidth=1) +geom_vline(aes(xintercept=VaR),color="brown", linewidth=1) +labs(title=glue("Distribution of TR: mu: {round(mu, 8)}, sigma: {round(sig, 6)}, VaR({alpha}): {round(VaR, 6)}"), y='count')return(p)}get_comp_plot <-function(s, alpha=0.05){ mu <-mean(s) sig <-sd(s) norm_s <-get_norm_series(mu, sig) VaR <- norm_s |>get_sim_VaR(); VaR ES <- norm_s |>get_sim_ES(VaR=VaR); ES s_sim <- s |>get_sim_series() VaR_sim <- s_sim|>get_sim_VaR(); VaR_sim ES_sim <- s_sim |>get_sim_ES(VaR=VaR_sim); ES_sim err_VaR <-err(VaR, VaR_sim) |>round(digits =2) err_ES <-err(ES, ES_sim) |>round(digits =2) p <-data.frame(TR=s_sim, TR2=norm_s) |>ggplot() +geom_density(mapping =aes(x=TR), alpha=.2, fill="violet") +geom_density(mapping =aes(x=TR2), alpha=.2, fill="white") +geom_vline(aes(xintercept=ES_sim),color="brown", linetype="dashed", linewidth=1) +geom_vline(aes(xintercept=ES),color="blue", linetype="dashed", linewidth=1) +geom_vline(aes(xintercept=VaR_sim),color="brown", linewidth=1) +geom_vline(aes(xintercept=VaR),color="blue", linewidth=1) +labs(title=glue("Distribution of TR alpha({alpha}): \n VaR_norm(blue): {round(VaR, 6)},VaR_sim(brown): {round(VaR_sim, 6)}, Error: {round(err(VaR, VaR_sim), 2)}% \n ES_norm: {round(ES, 6)},ES_sim: {round(ES_sim, 6)}, Error: {round(err(ES, ES_sim), 2)}%"), y='count')return(p)}do_analysis <-function(s, alpha=0.05){ modelname1 <-"Norm" VaR1 <- s |>get_VaR() |>as.double() ES1 <- s |>get_ES() |>as.double()# df[nrow(df) + 1,] <- c(modelname, VaR, ES) modelname2 <-"NormSim" norm_series <- s |>get_norm_series_from_s() VaR2 <- norm_series|>get_sim_VaR(alpha=alpha) |>as.double() ES2 <- norm_series |>get_sim_ES(VaR=VaR2) |>as.double()# df[nrow(df) + 1,] <- c(modelname, VaR, ES) modelname3 <-"T-Sim" t_series <- s |>get_t_series_from_s() VaR3 <- t_series|>get_sim_VaR(alpha=alpha) |>as.double() ES3 <- t_series |>get_sim_ES(VaR=VaR3) |>as.double()# df[nrow(df) + 1,] <- c(modelname, VaR, ES) modelname4 <-"Sim" sim_series <- s |>get_sim_series() VaR4 <- sim_series|>get_sim_VaR(alpha=alpha) |>as.double() ES4 <- sim_series |>get_sim_ES(VaR=VaR4) |>as.double() model_names <-c(modelname1, modelname2, modelname3, modelname4) VaRs <-c(VaR1, VaR2, VaR3, VaR4) ESs <-c(ES1, ES2, ES3, ES4)return(data.frame(ModelName=model_names, VaR=VaRs, ES=ESs))}get_multi_day_series <-function(s, days=10, sampling_func=get_sim_series, n=100000, set_seed=TRUE){if (set_seed){RNGkind(sample.kind="Rounding")set.seed(123789) } rvec <-rep(0, n)for( i in1:days){ rvec <- rvec +sampling_func(s=s, n=n, set_seed=FALSE)# print(rvec |> head()) }return(rvec)}get_multi_day_series_block <-function(s,days=10, n=100000, set_seed=TRUE){if (set_seed){RNGkind(sample.kind="Rounding")set.seed(123789) } rdat <- s |>as.vector() rvec <-rep(0, n) posn <-seq(from=1, to=(length(rdat)-days+1), by=1) rpos <-sample(posn, size=n, replace=TRUE)for( i in1:days){ rvec <- rvec + rdat[rpos] rpos <- rpos+1 }return(rvec)}do_multi_analysis <-function(rvec, days=10, alpha=0.05){ modelname1 <-glue("student-t({days})") fitspars <- rvec |>get_fit_params() #; fitspars sampling_func_tdist <-partial(get_t_series_from_s, fitpars = fitspars) s1 <- rvec |>get_multi_day_series(sampling_func=sampling_func_tdist) VaR1 <- s1 |>get_sim_VaR(alpha=alpha) |>as.double() ES1 <- s1 |>get_sim_ES(VaR=VaR1) |>as.double() modelname2 <-glue("IID({days})") s2 <- rvec |>get_multi_day_series(days=days) VaR2 <- s2 |>get_sim_VaR(alpha=alpha) |>as.double() ES2 <- s2 |>get_sim_ES(VaR=VaR2) |>as.double() modelname3 <-glue("consecutive({days})") s3 <- rvec |>logret_ndays(days=days) |>get_sim_series(set_seed =TRUE) VaR3 <- s3 |>get_sim_VaR(alpha=alpha) |>as.double() ES3 <- s3 |>get_sim_ES(VaR=VaR3) |>as.double() model_names <-c(modelname1, modelname2, modelname3) VaRs <-c(VaR1, VaR2, VaR3) ESs <-c(ES1, ES2, ES3)return(data.frame(ModelName=model_names, VaR=VaRs, ES=ESs))}expected_loss_df <-function(df, portfolio=1000){ expected_loss_port =partial(expected_loss, portfolio=portfolio) df$VaR <-sapply(df$VaR, expected_loss_port) df$ES <-sapply(df$ES, expected_loss_port)return(df)}
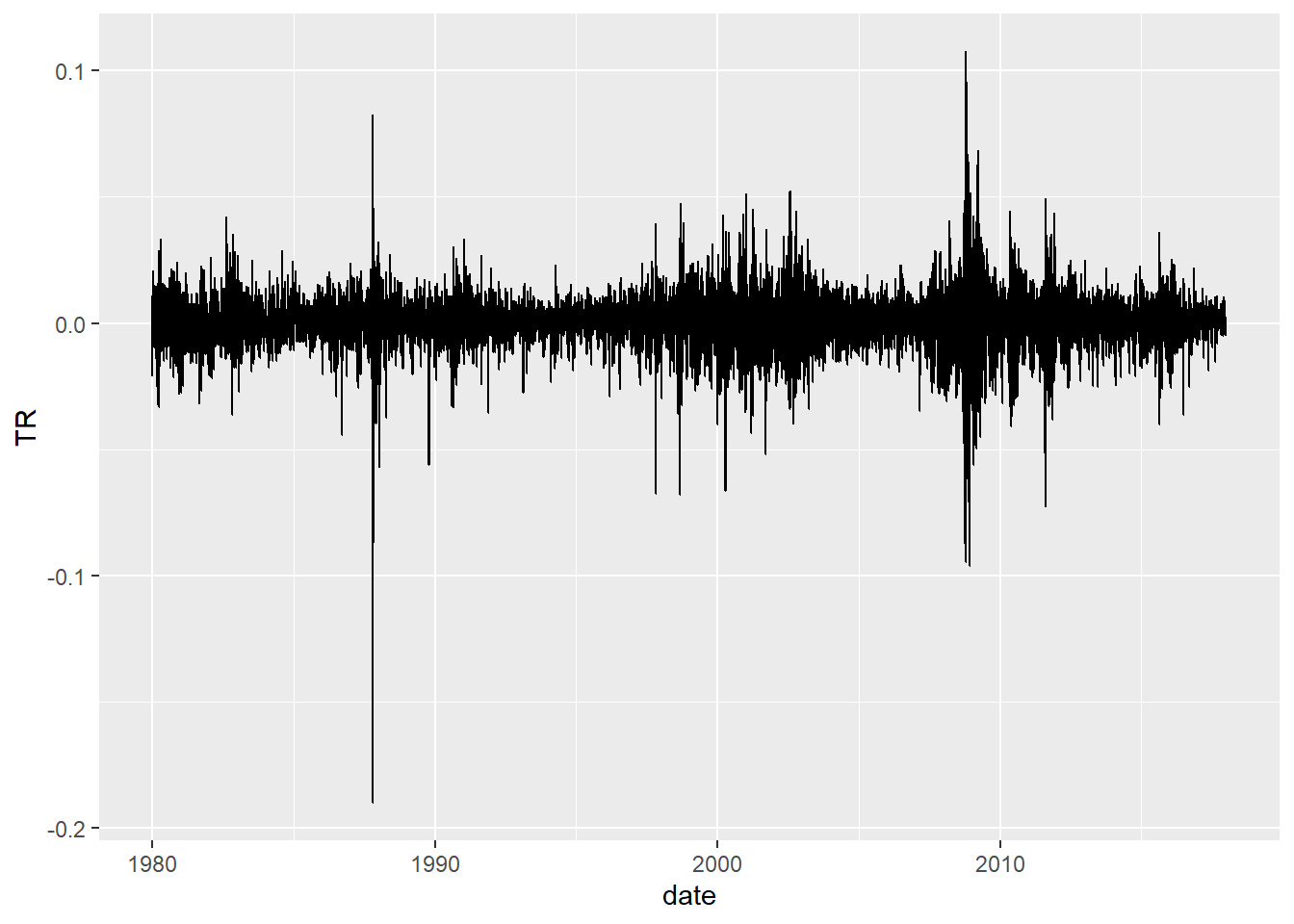
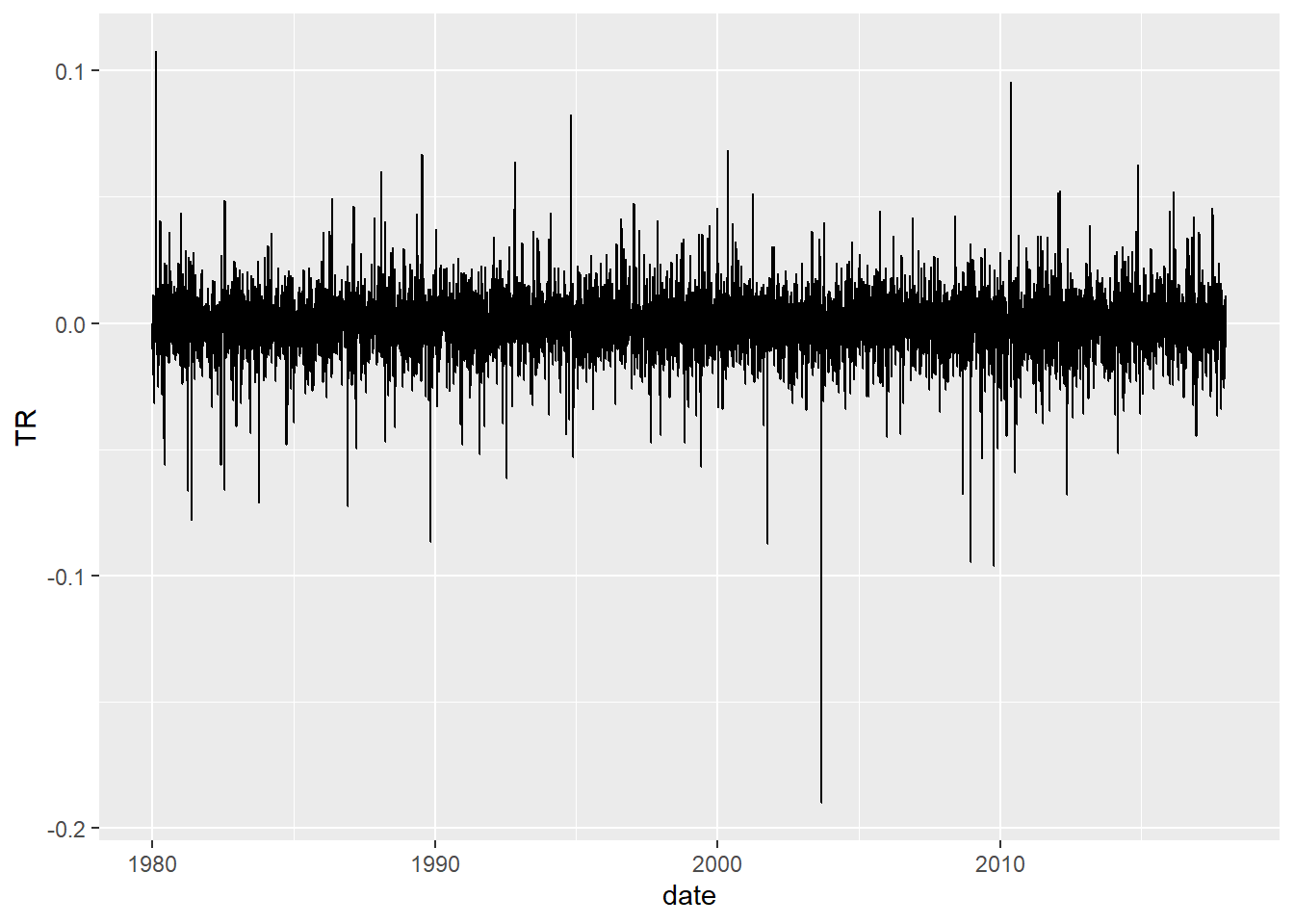
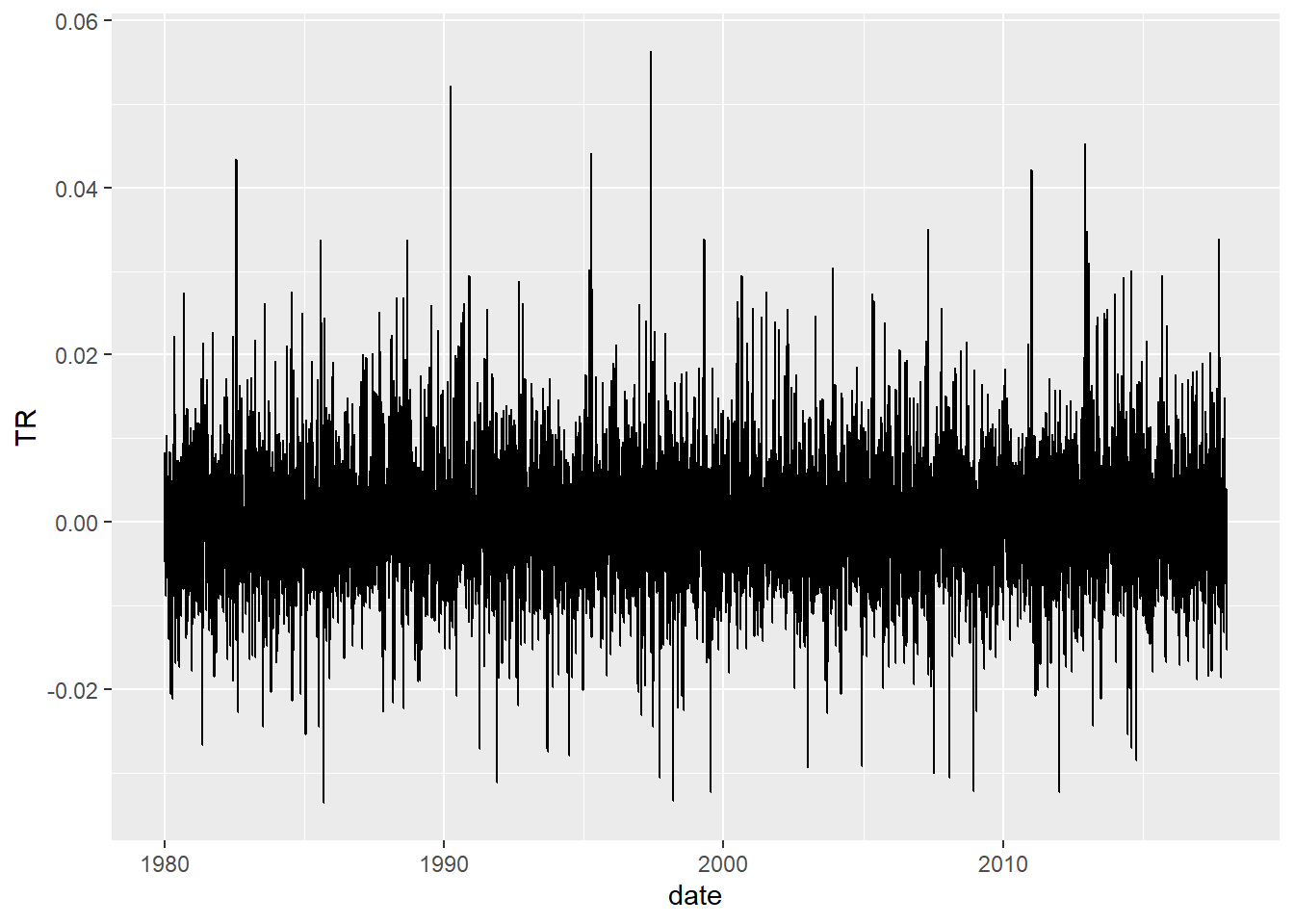
Future Vs Historical Distribution
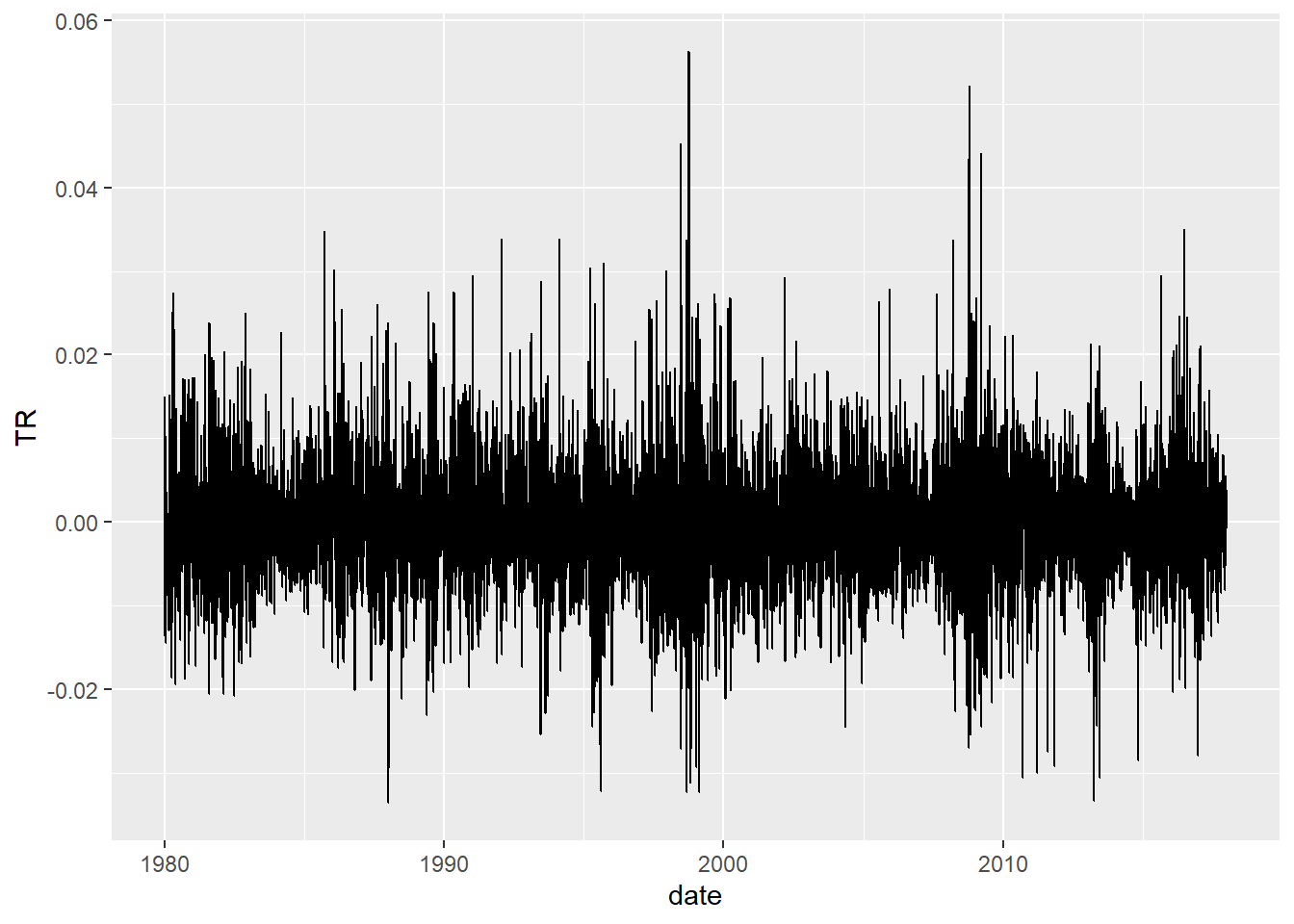
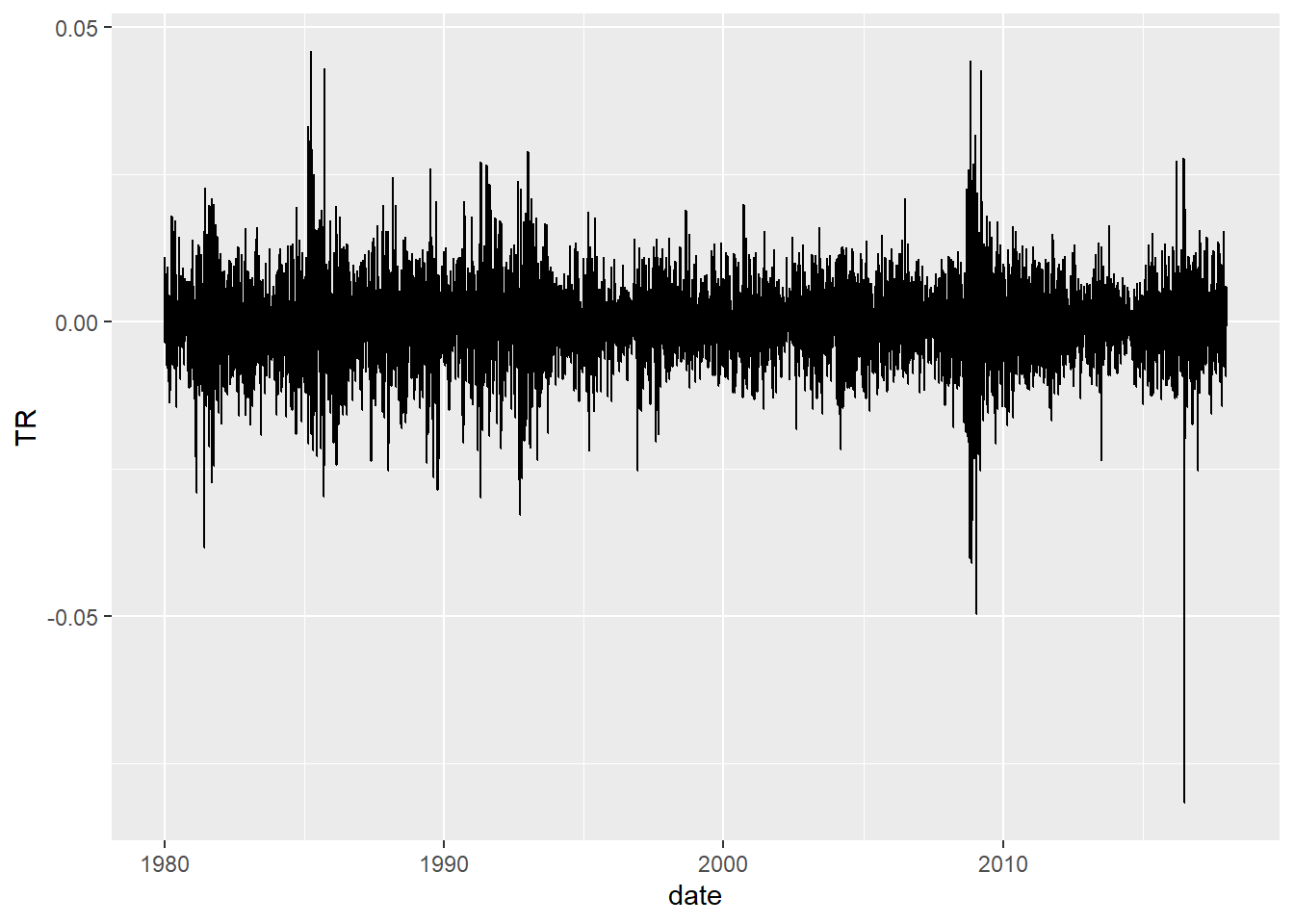
wilsh <-getSeries("WILL5000IND")wilsh |>head(2)
TR
1979-12-31 1.90
1980-01-02 1.86
wilsh |>tail(2)
TR
2017-12-28 124.33
2017-12-29 123.67
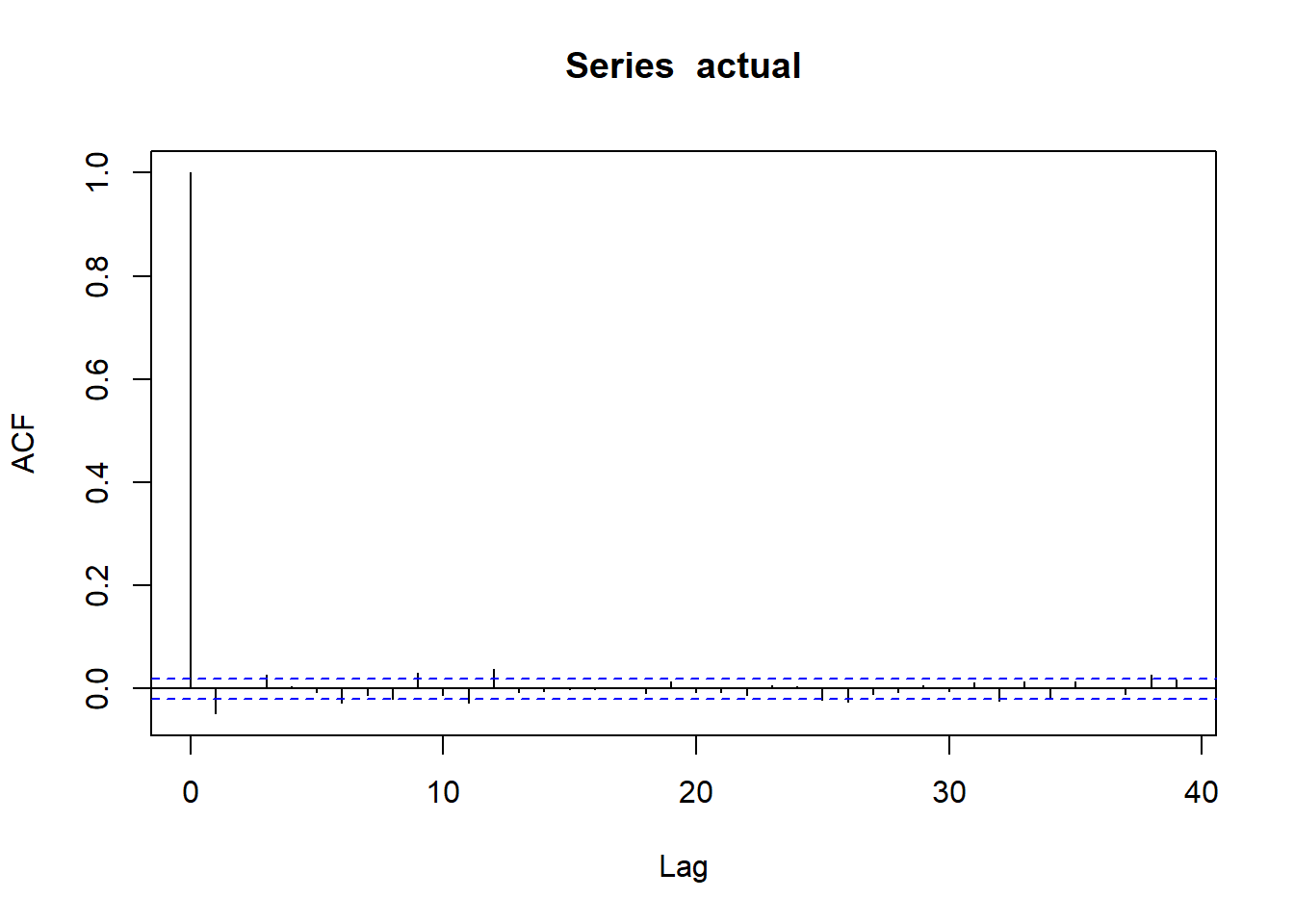
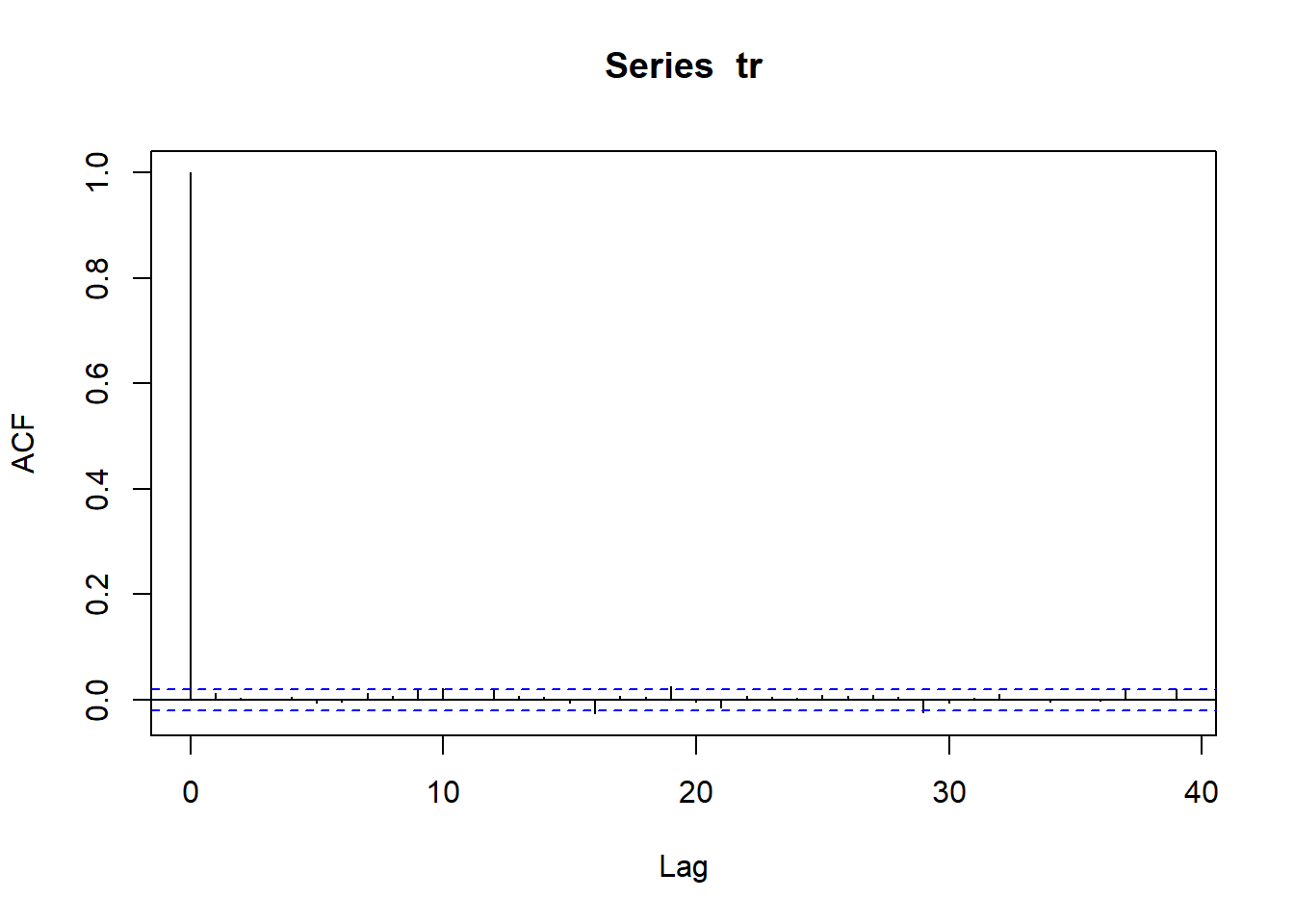
wilsh |>logret_1() |>acf()
ACF Intrepretation
Dashed lines represent 95% confidence interval for ACF
If many vertical lines are outside dashed band => We have evidence of serial correlation.
If all or most lines are inside dashed bands => no strong evidence of serial correlation.
Above plot shows , We do not find much evidence of serial correlation in the daily log returns of the Wilshire 5000 index. That means the direction of stock prices are not predictable.
Volatility Clustering
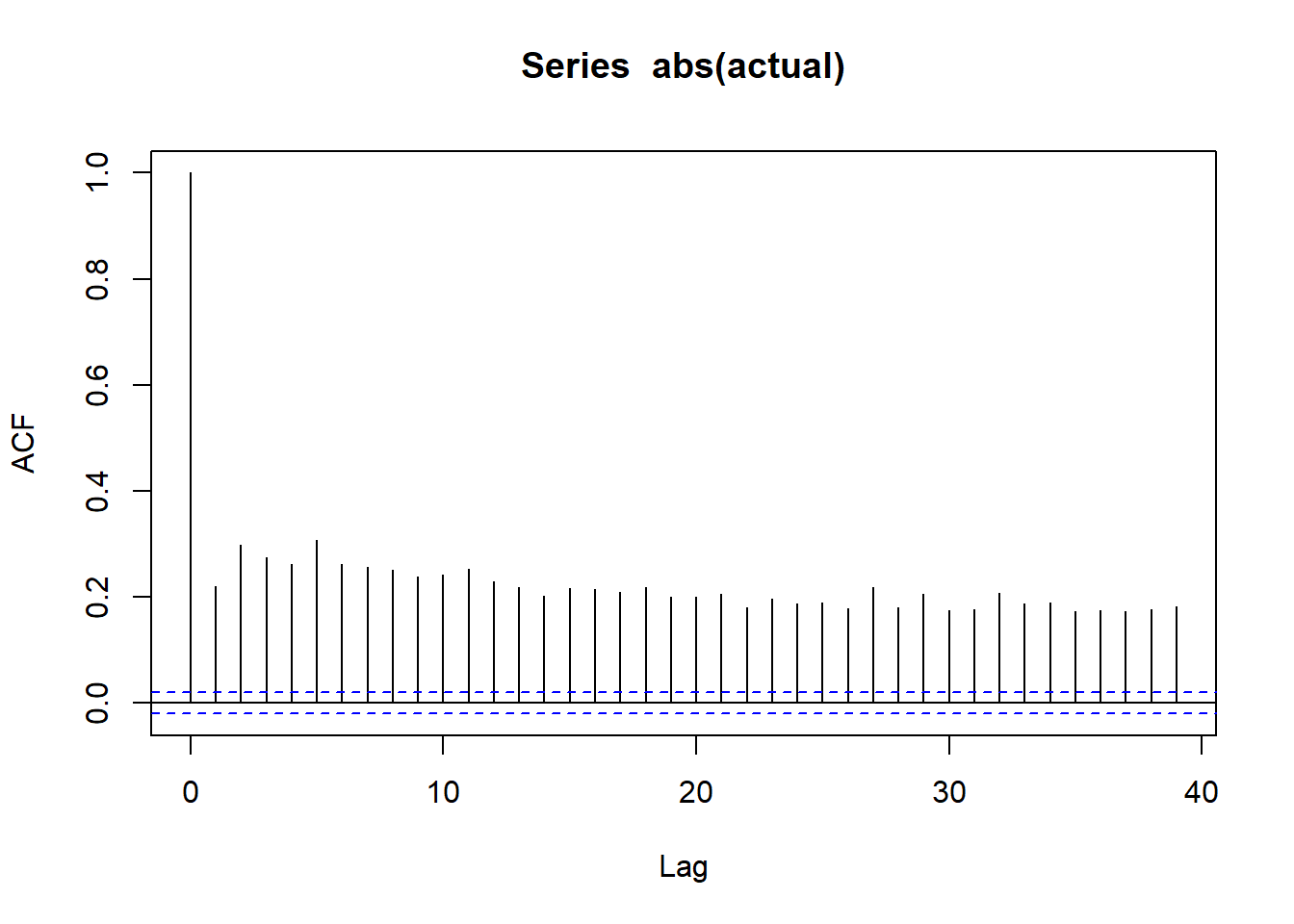
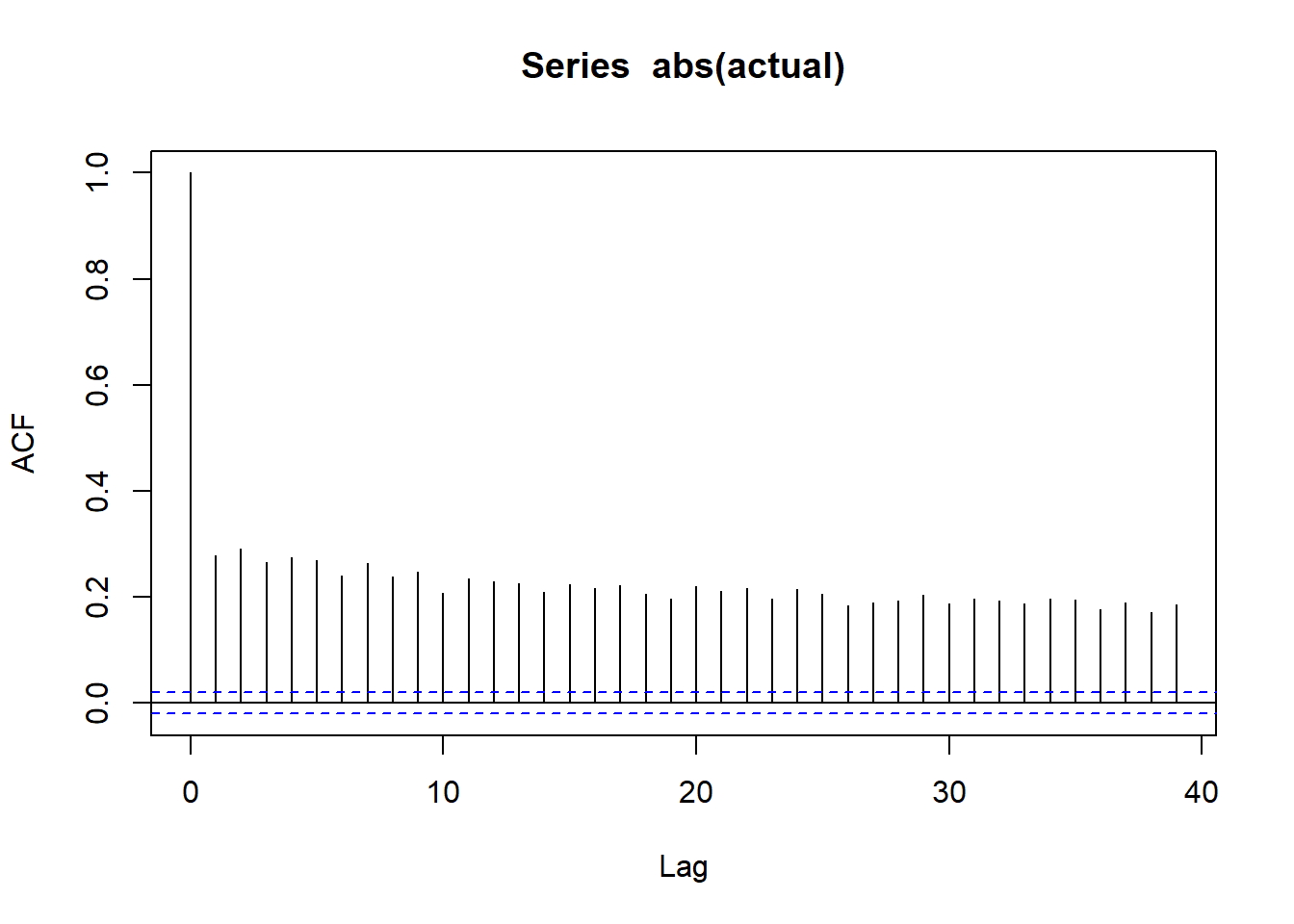
wilsh |>logret_1() |>abs() |>acf()
All lines for autocorrelation on absolute values are above dashed band showing strong possibility of serial correlation and thus volatility clustering
*---------------------------------*
* GARCH Model Spec *
*---------------------------------*
Conditional Variance Dynamics
------------------------------------
GARCH Model : sGARCH(1,1)
Variance Targeting : FALSE
Conditional Mean Dynamics
------------------------------------
Mean Model : ARFIMA(0,0,0)
Include Mean : TRUE
GARCH-in-Mean : FALSE
Conditional Distribution
------------------------------------
Distribution : norm
Includes Skew : FALSE
Includes Shape : FALSE
Includes Lambda : FALSE
g <- save1$zg |>as.vector() |>mean() |>round(digits=4)
[1] -0.0309
g |>as.vector() |>sd() |>round(digits=4)
[1] 1.0006
g |>as.vector() |>skewness() |>round(digits=2)
[1] -0.59
g |>as.vector() |>kurtosis() |>round(digits=2)
[1] 6.44
g |>as.vector() |>jarque.test()
Jarque-Bera Normality Test
data: as.vector(g)
JB = 5292.3, p-value < 2.2e-16
alternative hypothesis: greater
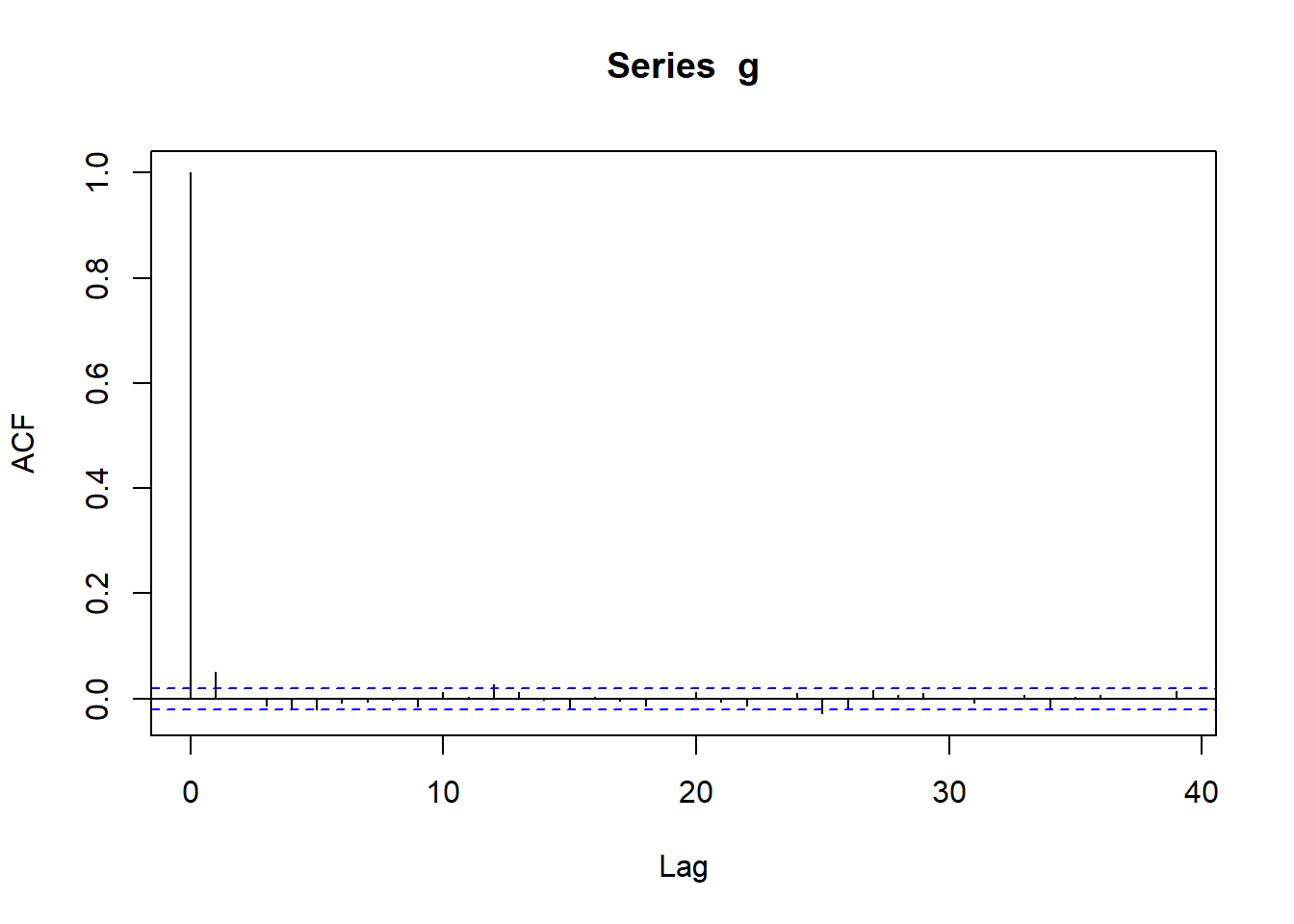
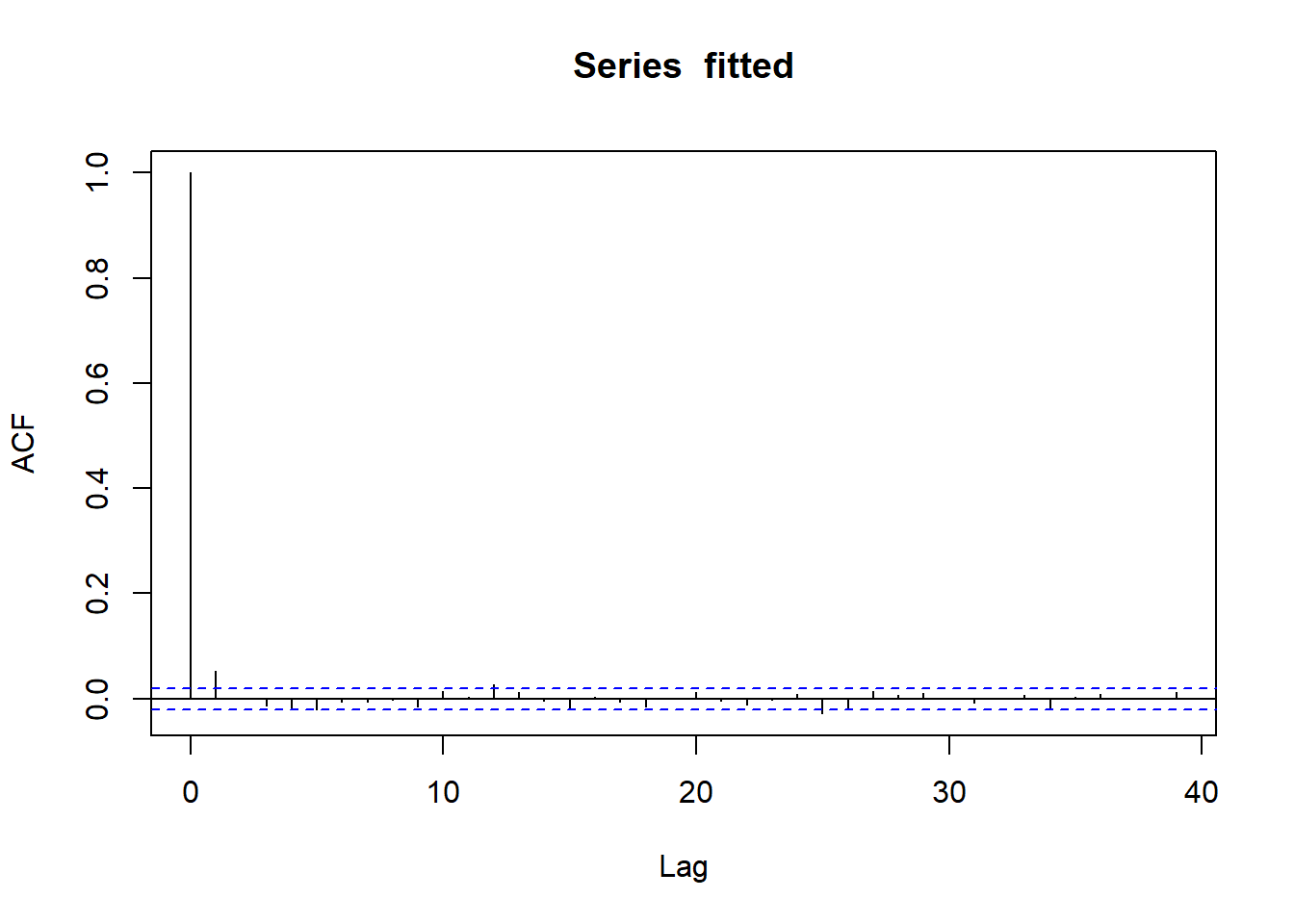
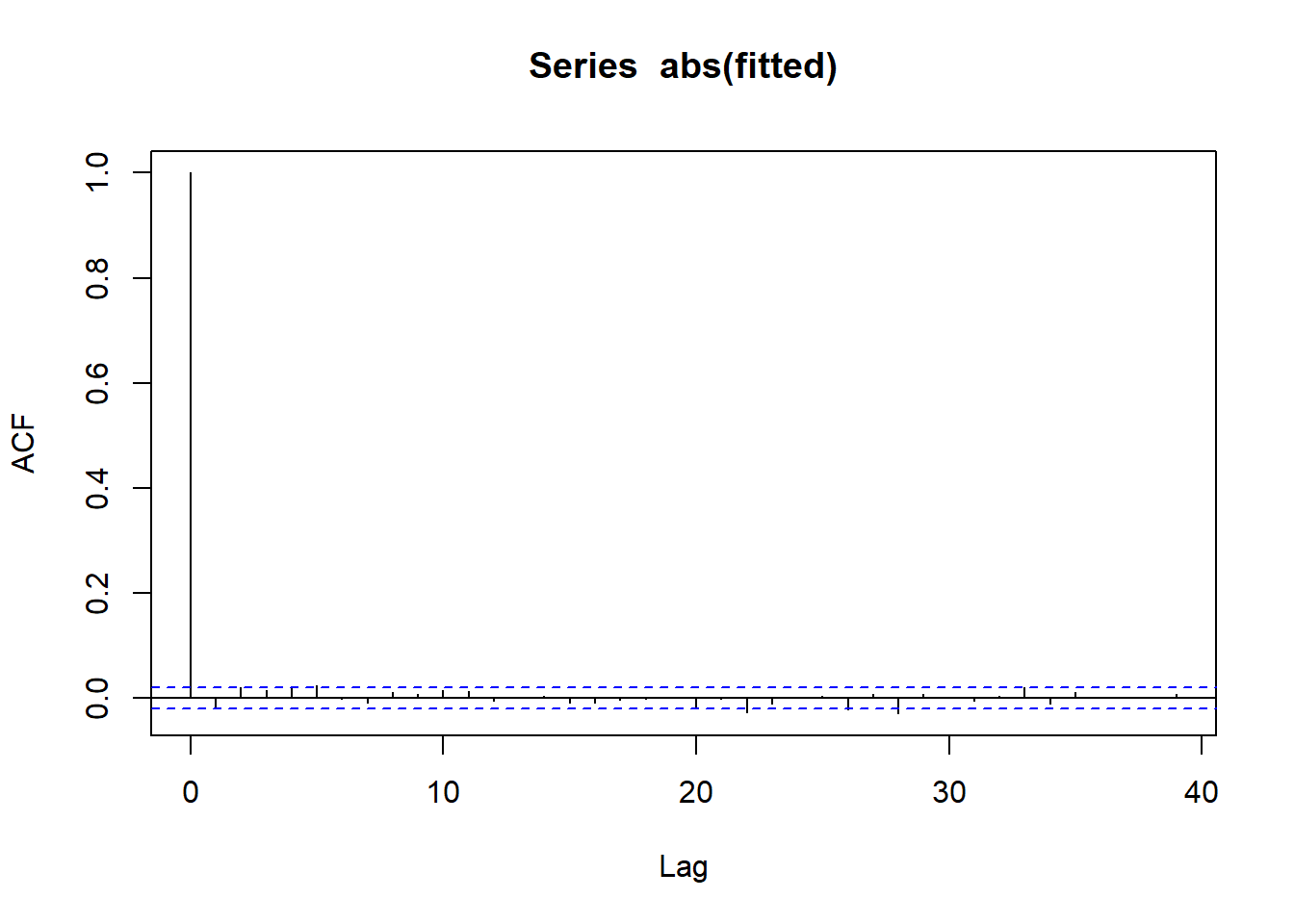
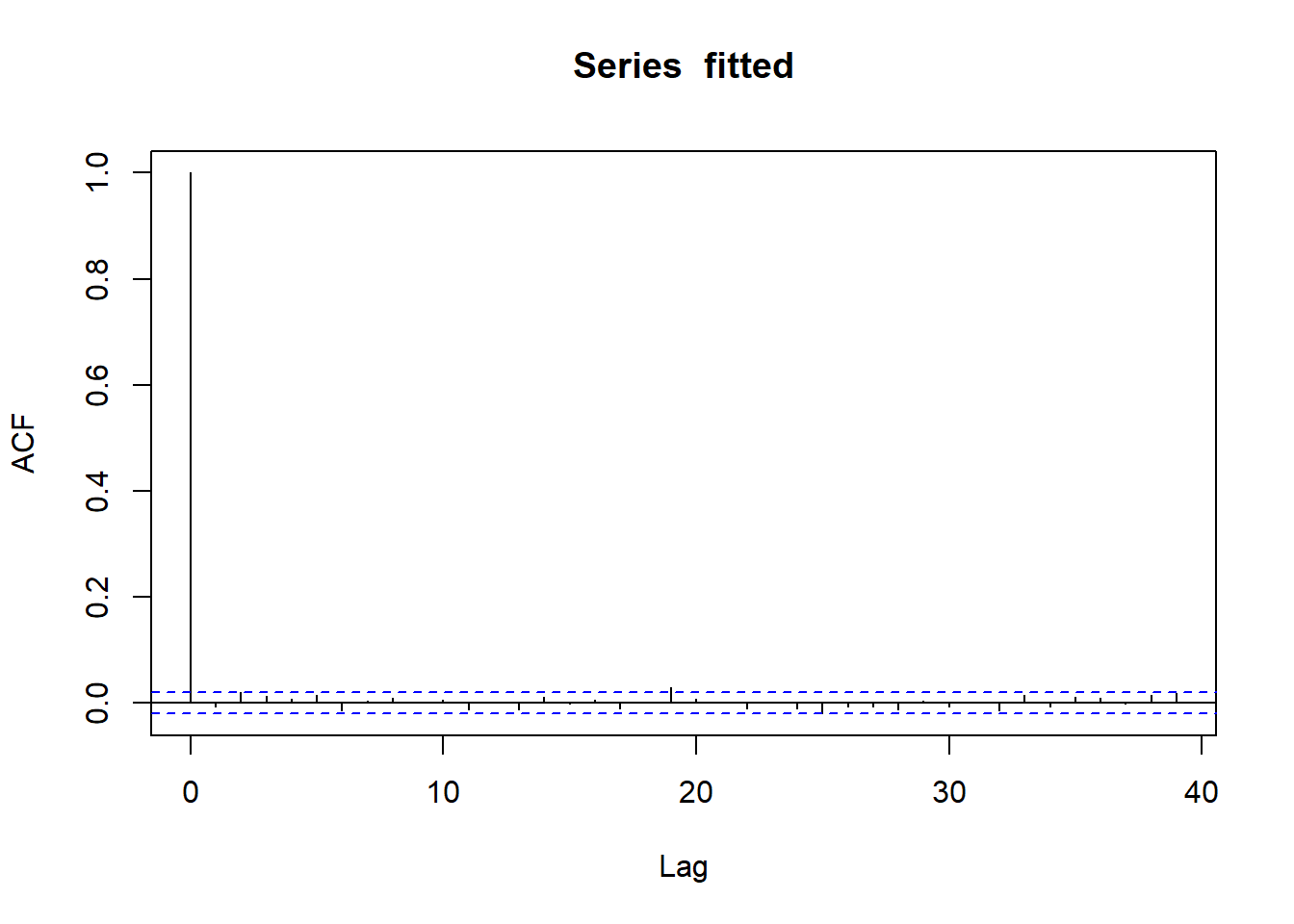
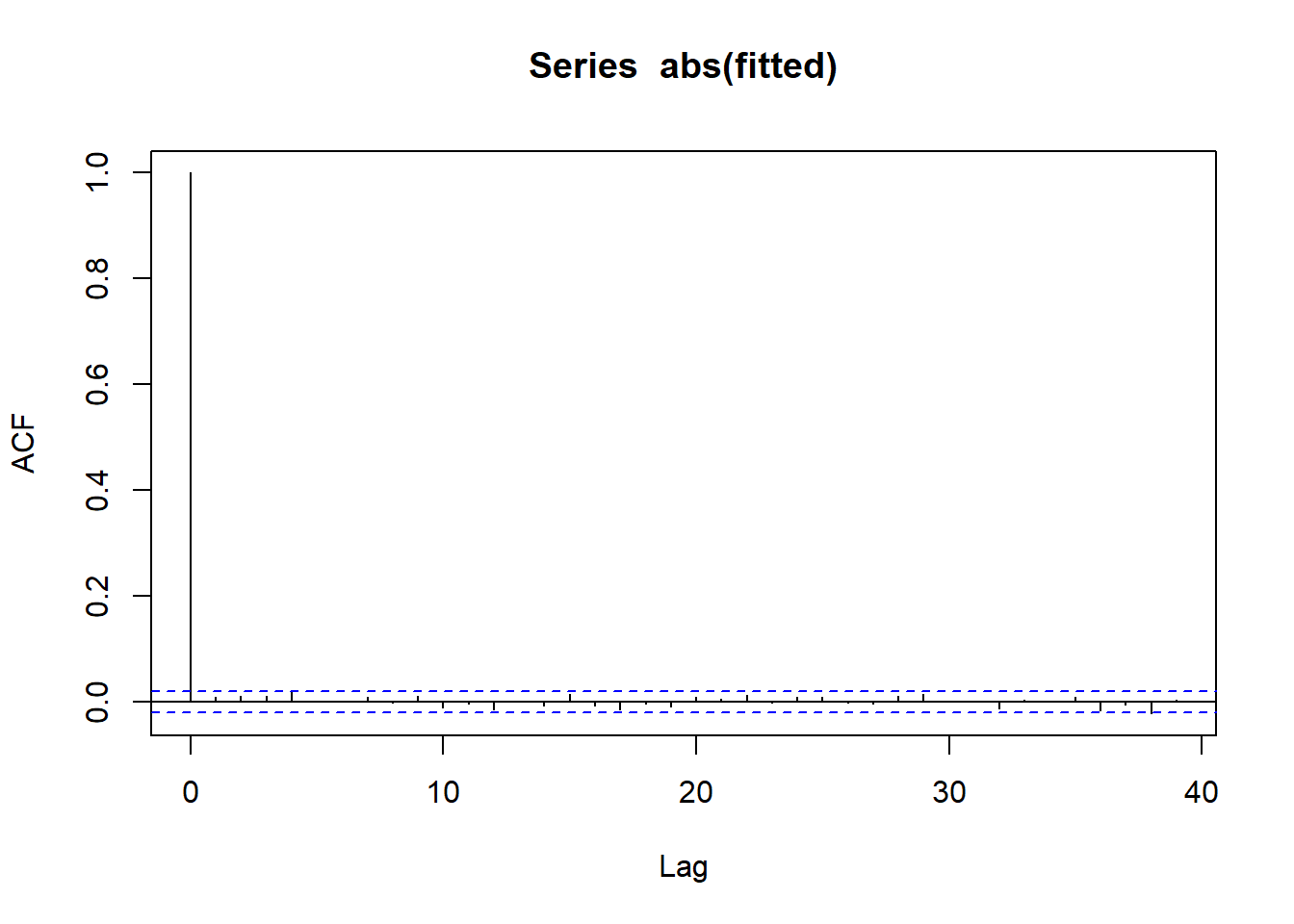
g |>acf()g |>abs() |>acf()
ACF of fitted e(t)
ACF of |fitted e(t)|
g <- save1$logretg |>as.vector() |>mean() |>round(digits=4)
[1] 4e-04
g |>as.vector() |>sd() |>round(digits=4)
[1] 0.0107
g |>as.vector() |>skewness() |>round(digits=2)
[1] -0.91
g |>as.vector() |>kurtosis() |>round(digits=2)
[1] 21.8
g |>as.vector() |>jarque.test()
Jarque-Bera Normality Test
data: as.vector(g)
JB = 142514, p-value < 2.2e-16
alternative hypothesis: greater
t <- g |>as.vector() |>jarque.test()t$statistic
JB
142514.5
t$p.value
[1] 0
t$alternative
[1] "greater"
Interpretation of Garch(1,1) - normal model
For a normal distribution to be true fitted e(t) should have
mean=0, sd=1, skewness=0, kurtosis=3
Jacque bera test should be able to confirm normality
Kurtosis of our data is around 21.8 . Our fitted distribution is around 6.44 and normal distribution expects it to be 3 => GARCH model is able to explain quite a lot but not all of the heavy tail
ACF curves for fitted value indicated no serial correlation
ACF curves for absolute fitted value indicate no serial correlation and thus, no volatility clustering => Variance equation in GARCH model is able to explain all volatility clustering in our data
Conclusion: GARCH(1,1) - normal model can explain
Volatility clustering of our data
Some but not all of heavy tails of the data
To have better explanation of distribution we need to change distribution equation.
g <- gold |>filterSeries() |>logret_1()g |>head(2)
TR
1980-01-03 0.12500543
1980-01-04 -0.07532201
g |>tail(2)
TR
2017-12-27 0.011674890
2017-12-28 0.009025894
g |>do_analysis_garch_nextday(date.ends=c("2017-12-29","2008-09-15","1987-10-19")) |>format(digits=5)
Warning in RNGkind(sample.kind = "Rounding"): non-uniform 'Rounding' sampler
used
Warning in RNGkind(sample.kind = "Rounding"): non-uniform 'Rounding' sampler
used
Warning in RNGkind(sample.kind = "Rounding"): non-uniform 'Rounding' sampler
used
g |>get_garch_VaR_plot(refit.every =100, alpha =0.05)
Warning in RNGkind(sample.kind = "Rounding"): non-uniform 'Rounding' sampler
used
Warning in RNGkind(sample.kind = "Rounding"): non-uniform 'Rounding' sampler
used
Warning in RNGkind(sample.kind = "Rounding"): non-uniform 'Rounding' sampler
used